NSSCTF 2025 4th Reverse WP
checkit
java 层
附件是 apk, java 层没什么东西
MainActivity 如下,关键在于调用了本地方法 checkInput
1 | |
native 层
导出 libcheck.so 文件
在 Java_com_test_ezre_MainActivity_checkInput 函数里面找到关键处
exec(code, *v4)
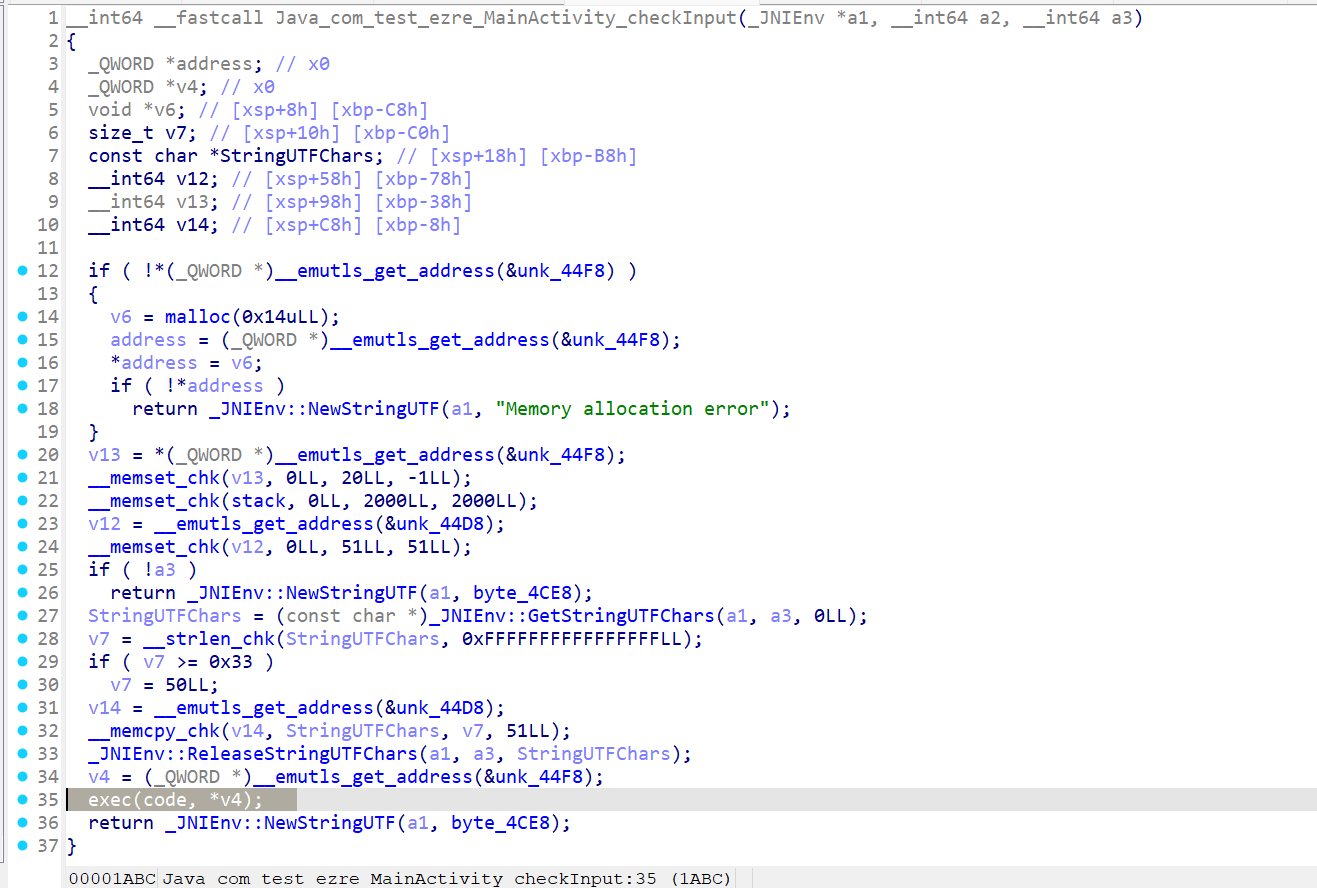
点进这个函数,再跳转一次后,发现是一个 vm
1 | |
操作码就是刚刚的 code
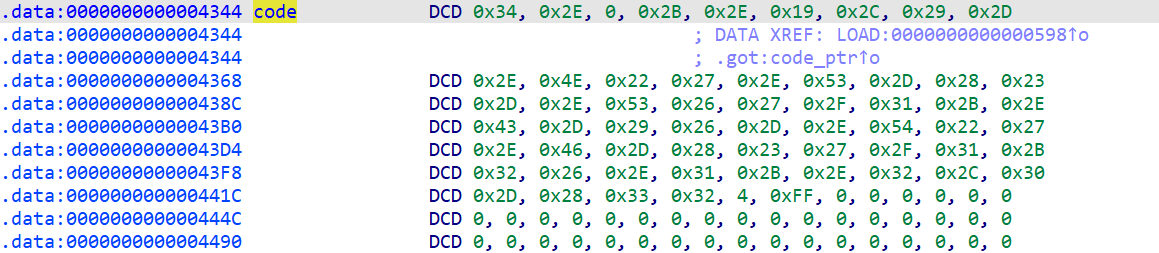
在 vm 还中发现一个 cmp_data

分析这个 vm 可以知道它使用了四个寄存器来存值,第一个用于临时存储和算术运算,第二个用于索引输入字符串和 cmp_data 数组,第三个用于循环计数,第四个用于临时存储,把它们记为 A、B、C、D,还用了一个栈来存储数据
同构出 vm python 脚本来 trace 加密过程,跟之前写的 vm 同构脚本相比这次在 ai 的帮助下换了一种写法,写了一个单独的 trace 函数来打印每一步的状态,感觉比原来的要便捷很多
同构 vm
1 | |
运行结果是
1 | |
里面加载了几个立即数,打印出来可以发现是 flag 的开头
1 | |
分析 解密
同时还可以看出对奇数索引和偶数索引的处理方式不同
input[0] (偶数索引)
1 | |
input[1] (奇数索引)
1 | |
总结出来加密逻辑大概是
1 | |
那么解密就应该是
1 | |
从 C 的值可以看出,一共有 0x19(25) 轮加密,一次加密两个字符,而刚好 cmp_data 的长度为50
解密脚本
1 | |
flag 为
NSSCTF{C0ngr@tulation!Y0N_s33m_7o_b3_gO0d_@t_vm!!}
CrackMe&F***Me
开始做的时候给我看得一头雾水,找不到方向,梳理做完之后还是有收获的
(讨厌这个出题人.jpg)
魔改 PyInstaller
附件(改名为 crack.exe了) 用 DIE 查看是 PyInstaller
打包的,起初直接用工具 pyinstxtractor-2025.02 解包失败了
python pyinstxtractor.py crack.exe
报错如下

Missing cookie 说明 exe 中找不到 PyInstaller 的标识
然后就尝试用 010 editor 来修复文件,找了两能够被正常解包的 python 程序来进行对比,最后发现这样改成这样的话是能够被识别然后解包的(解包时用与打包相同的 python 版本,此处是用的 3.8)
再次解包,仍然有报错
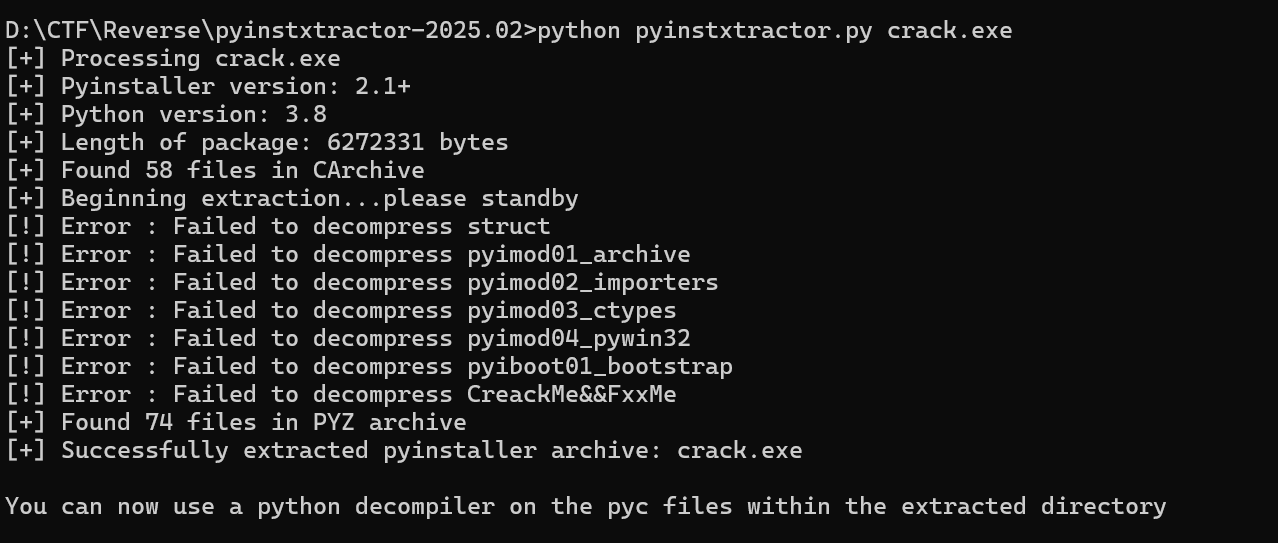
成功识别 PyInstaller 版本,但在解压 exe 内部的模块是发生错误
解决办法仍是把这个程序和正常打包的 python 程序在 ida 中进行对比,观察哪个函数进行了魔改,从头对比,观察到在 sub_140001450 处函数的地址不一样了,说明上个函数(sub_1400011F0)就是被魔改的函数
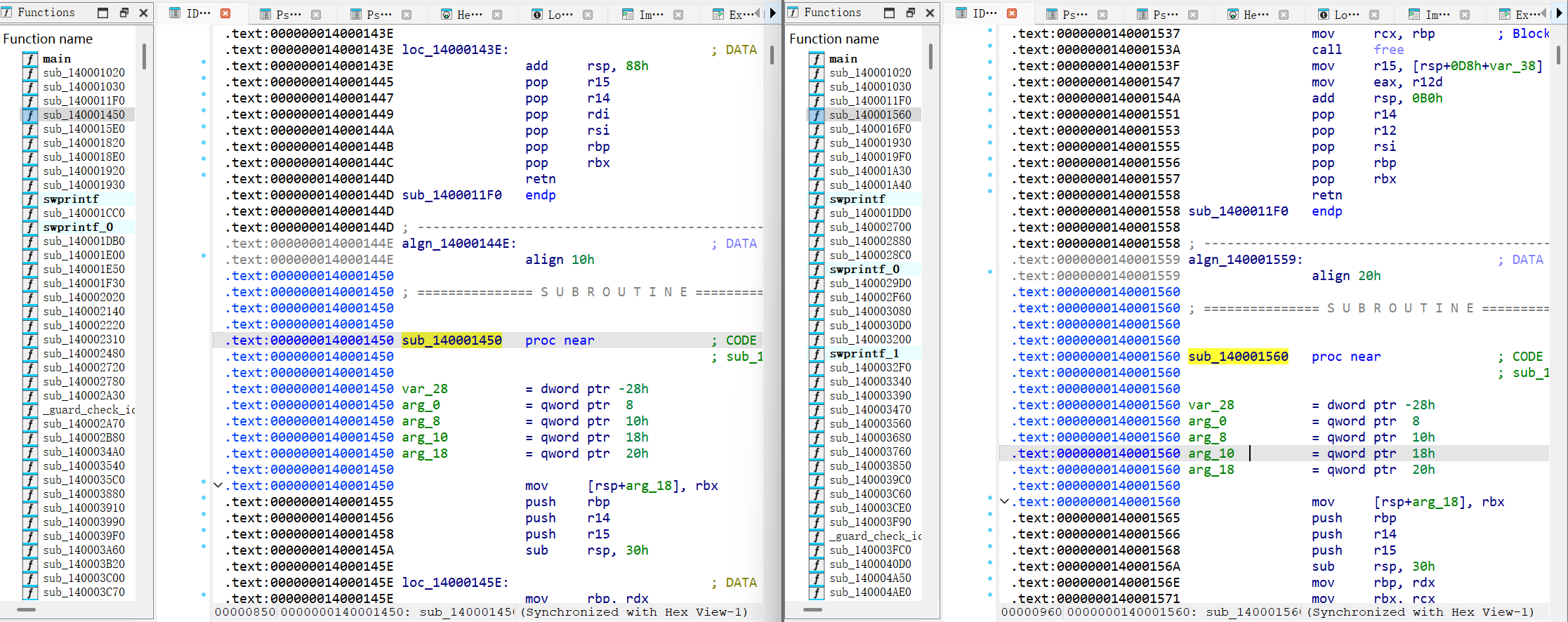
魔改的 sub_1400011F0
1 | |
与正常的相比,这个的主要改动在于:
检测首 4 字节如果是 “swdd” 则将 buffer 向前移 4 字节(丢弃 “swdd” )
数据块前 64 字节分组:每组 64 字节 = 16B × 4,用 16B 的常量向量si128 异或,剩余不足 64 字节的部分每字节 ^0xAA
研究 pyinstxtractor.py 源码,修改,添加上述功能
添加处理标头 swdd 和进行 xor 的函数
1 | |
并且在 extractFiles 函数中新增了一行
data = self._maybe_xor_decode(data)
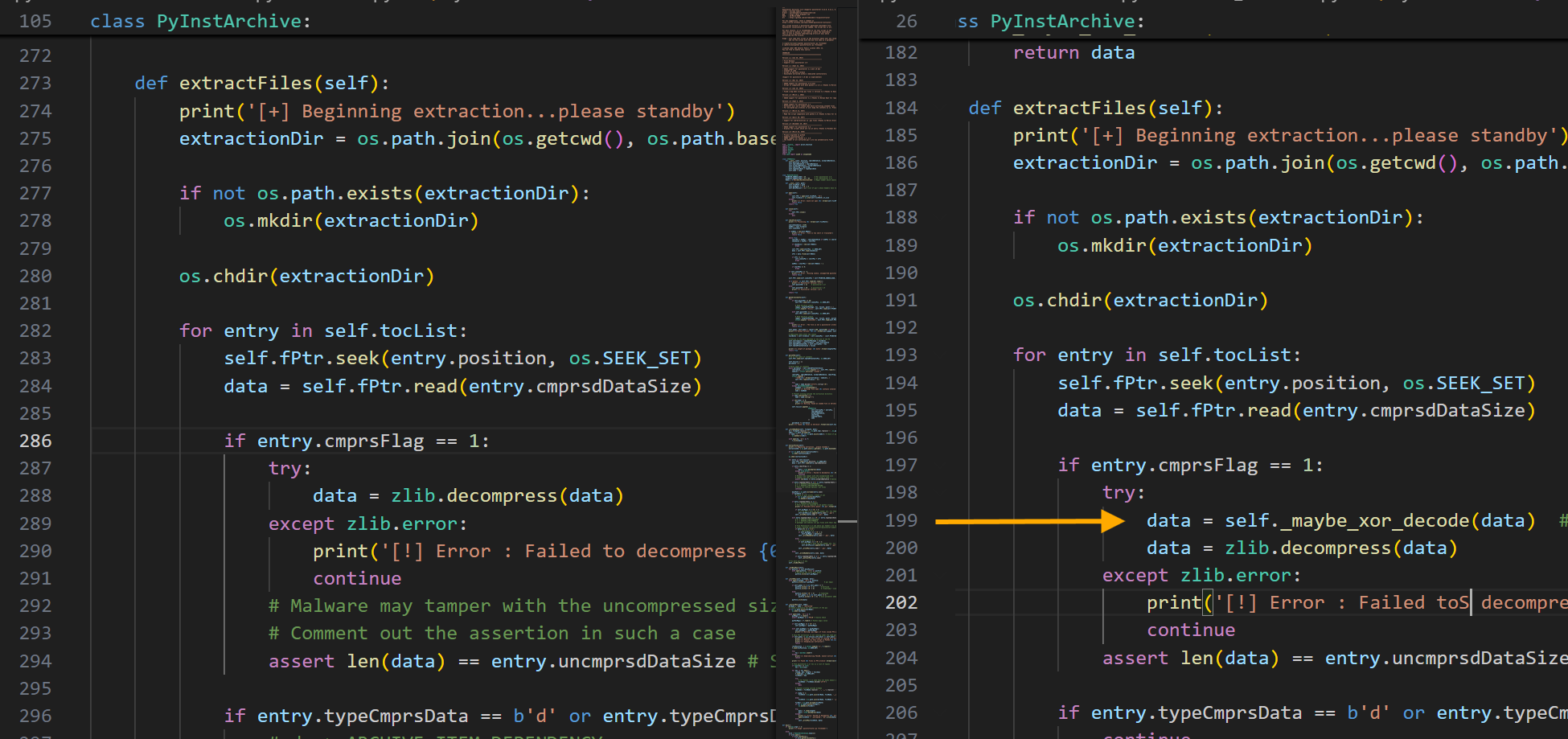
使用修改后的 pyinstxtractor.py(完整代码贴在文末了) 重新解包,这次全部成功了
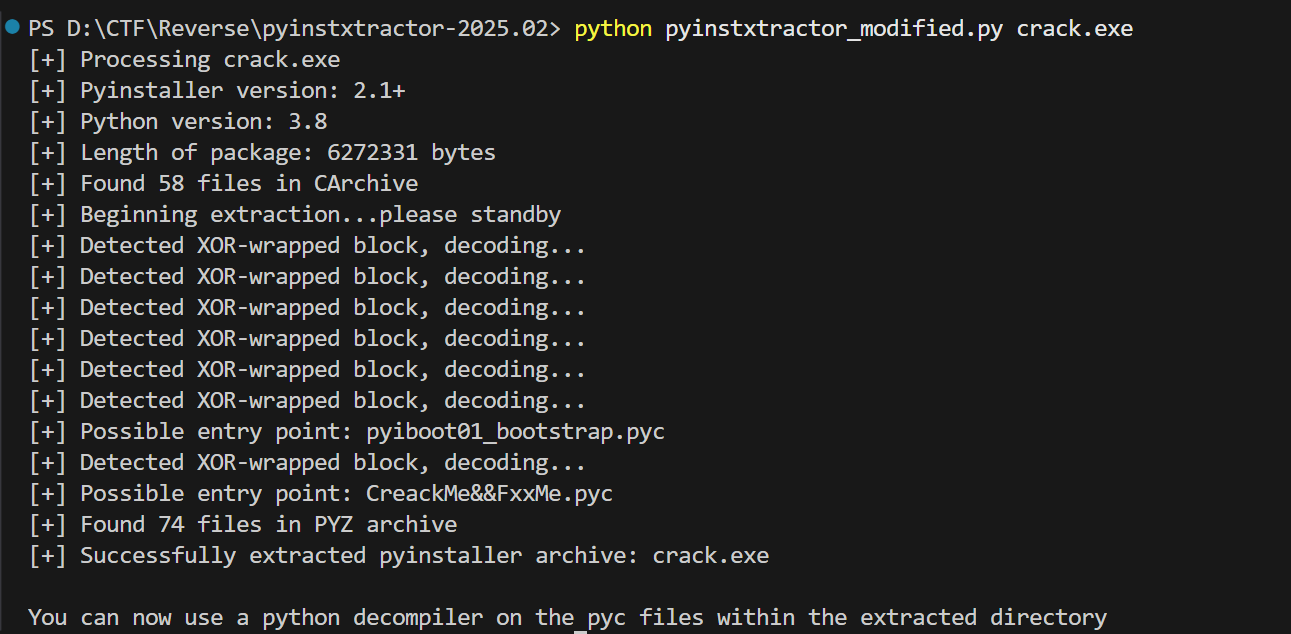
pyc 反编译 解密
在提取出的 crack.exe_extracted 文件夹中找到 CreackMe&&FxxMe.pyc,在线反编译一下,得到
1 | |
开始看到中间两行的 S[i] = S[j] 和
S[j] = S[i]以为是魔改,还去整了好一会儿爆破脚本…
后面直接当成标准 RC4 来处理,得到 flag 了
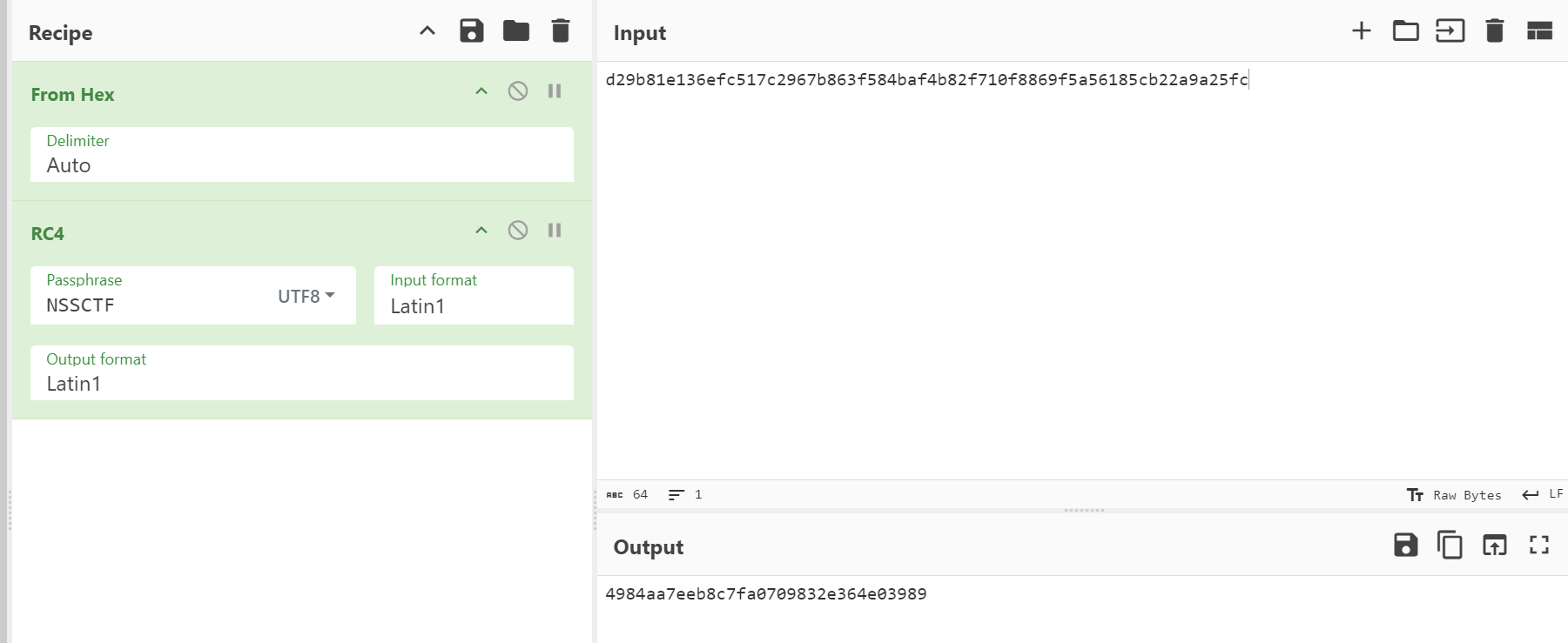

flag 为 NSSCTF{4984aa7eeb8c7fa0709832e364e03989}
pyinstxtractor_modified.py
1 | |