逆向三道题出了两道,另一道纯恶心人来的
发现晚上出 flag 概率比白天高 =w=
pixelflow
初步分析
找到 global-metadata.dat 和
GameAssembly.dll 用 il2cppdumper 解包
但是在 Assembly-CSharp.dll 没看到什么东西 于是开始分析
GameAssembly.dll,参考 普通PC端IL2Cpp
Unity游戏逆向方法体代码记录
反编译结果分析:
Controller___Check_b__18_0_d__MoveNextSubstring(7, len-8),要求长度恰好
16
Controller___Check_b__18_1_d__MoveNextTexture2D(16,1, format=63),用 Color32
写入:R=byte[i], G=0, B=0, A=255,SetPixels32 + Apply,然后
Graphics.CopyTexture 到 TexF,说明 K0 输出的
16 字节正是 TexF 的 R 通道
Controller___Check_b__18_2_d__MoveNextComputeBuffer(16,4),命名 Buffer0,绑定到
Shader0 的 Buffer0,绑定 TexF 到
Shader0 的 TexF,设置 K2 常量(4
个 float),调用 Dispatch(Shader0, K0, 1,1,1),说明 K0
是加密的线程组数
Controller___Check_b__18_3_d__MoveNextBuffer0,Dispatch(Shader0, K1, 1,1,1),若输入无效(bytes
为空),直接把 Buffer0[0]=1(失败标志)
Controller__Check_d__18__MoveNextTexF,连续运行 3 次
runEncryptAsyn,运行
runCheckAsync,若输入无效:直接置
Buffer0[0]=1
纹理数据
用 AssetRipper 找纹理数据,在
sharedassets0.assets 里有个 ComputeShader 类的
Shader,Yaml 中找到 K0 K1
K2 的 code,先存成 .bxdc
文件然后用 HLSLDecompiler 反编译成 hlsl
文件
K0.hlsl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 // ---- Created with 3Dmigoto v1.2.45 on Sun Feb 1 01:10:35 2026
K1.hlsl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 // ---- Created with 3Dmigoto v1.2.45 on Sun Feb 1 01:10:41 2026
K2.hlsl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 // ---- Created with 3Dmigoto v1.2.45 on Sun Feb 1 01:10:44 2026
主要逻辑
K1 的核心逻辑 :
读取 u0[x](来自 K0 输出纹理)
计算 u0[x] + x(按 8-bit 截断)
读取 t0[x](来自 ciTex 纹理)
若不相等则失败
因此有:
t 0[x ] = (u 0[x ] + x ) m o d 256
从而目标字节为:
t a r g e t [x ] = (t 0[x ] − x ) m o d 256
K0 的 VM 指令序列(来自 coTex.png)等价于对
16 字节循环一次的变换,关键点:初始化寄存器:x1[1]=42, x1[2]=0;
对每个索引 i(0..15):
x = u0[i]
x = x ^ a(a 为累加器,初始 42)
x = ROL8(x, i & 7)
x = (x * 7) mod 256
x = (x + i) mod 256
out[i] = x
a = (a + x) mod 256
正向模拟 K0 VM 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import numpy as npdef solve_vm ():"e98e8a8ab7e7c9e0b897b74b3b21d37cbc8acfd5a8812ea8a3d2946bba809d" int (ci_hex[i:i+2 ], 16 ) for i in range (0 , 32 , 2 )]"0001002a00020000010002000200010003000200040000070600020007020000060100000502020108020010090000f70a00000000020012020001000400000607020000060202050900009001010109050100030801014a05010003" for i in range (0 , len (co_hex), 8 ):8 ]if len (pix) == 8 :int (pix[j:j+2 ], 16 ) for j in range (0 , 8 , 2 )])0 ] * 32 0 ] * 16 0 0 for _ in range (1024 ):if pc >= len (bytecode):break 0 ]1 ]2 ]3 ]1 if op == 0 :elif op == 1 :15 elif op == 2 :0xFF elif op == 3 :7 0xFF 8 - shift))) & 0xFF elif op == 4 :0xFF elif op == 5 :0xFF elif op == 6 :0xFF elif op == 7 :15 ] = x1[z] & 0xFF elif op == 8 :1 if x1[y] < w else 0 elif op == 9 :if w < 128 else w - 256 if cond:1 else :break return x0print (f"key: {key} " )
主流程里 runEncryptAsync 连续执行 3 次,所以最终供
K1 校验的 u0 是
u0 = K0(K0(K0(input))) 因此需要对 target
反向执行 K0 的逆变换三次,得到原始输入字节
x = (out[i] - i) mod 256
x = x * 7^{-1} mod 256,其中 7−1 ≡ 183 m o d 256
x = ROR8(x, i & 7)
x = x ^ a
a = (a + out[i]) mod 256
将这个逆过程对 target 重复 3 次
EXP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from PIL import Imagedef inv_round (out_bytes ):42 183 0 ] * 16 for i in range (16 ):0xFF 0xFF 7 8 - s)) & 0xFF )) & 0xFF 0xFF return inpdef main ():open ("ciTex.png" ).convert("RGBA" )0 ))[0 ] for x in range (16 )]0xFF for i in range (16 )]for _ in range (3 ):print ("target" , target)print ("input" , v)print ("hex" , "" .join(f"{b:02x} " for b in v))print ("ascii" , "" .join(chr (b) if 32 <= b <= 126 else "." for b in v))if __name__ == "__main__" :
flag 为 alictf{5haderVM_Rep3at!}
Thief
流量包分析
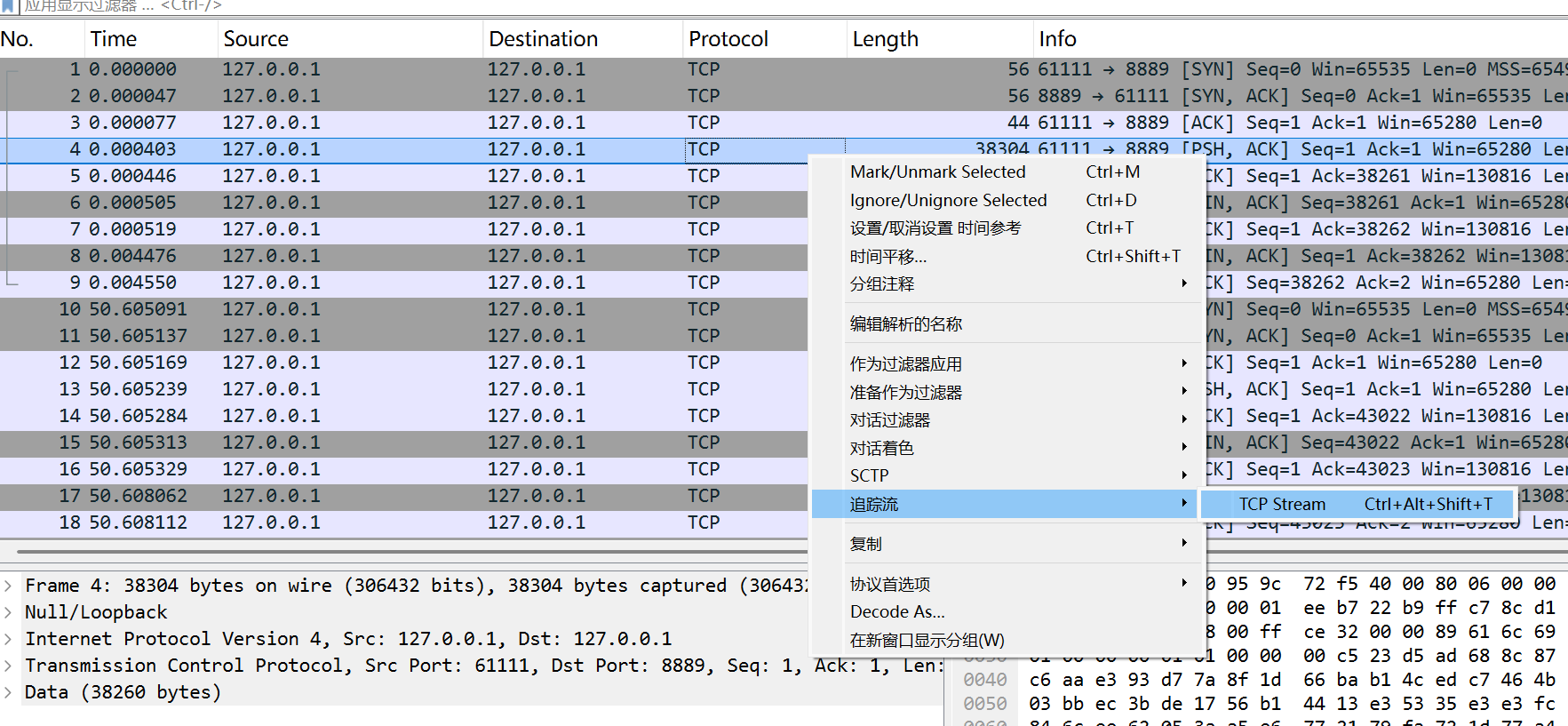
分析流量包,里面有三个数据流,从 Wireshark 导出那 3 个 TCP
流的原始数据
用 010 看会发现每条消息的开头都是 0x89 "ali",结构为
magic(4) + partIdx(4) + rsaLen(4) + rsaBlob(rsaLen) + fileCount(4) + [nameLen + nameXor + offset]* + payload,其中
nameXor 每字节异或 233
可以得到真实文件名,offset 指向 payload 内各
LZRR 块起始位置
三条流内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 part1: /Image1Part3.java /Image1Part1.java part2: /Image1Part4.java /Image1Part2.java part3: /Image1Part5.java / Image1Part6.java
webp 文件分析
Thief-hdpi 这个目录下有很多 .webp
文件,并且其中有的名字还带有混淆,应该属于是比较关键的内容
发现 .webp 开头是 CA FE BA BE,实际上是
Java class,对其进行反编译:
i.l.L 负责扫描 user.dir
上级目录并批量打包,每 3 个文件一组
i.l.l1I 内嵌 base64 数据段,解码得到两份算法表(记为
algo2/algo3)
i.l.l1I 负责打包:文件内容先经 i.l.Il1
压缩为 LZRR 格式;文件名 UTF‑8 后与 233 异或;offset
为每个文件压缩块的拼接偏移
i.l.Il1 产生的头部是大端
"LZRR" + ver(0x0201) + flag + in_len + crc - flag=13:直接
LZ 比特流;flag=15:先 RLE(0xFF 作为转义与游程标记),再进入 LZ
比特流。 - LZ 采用 1bit 标志区分字面量/匹配,offset 8/16 位可变,length
为 3+ 编码值
从 l1I 的 base64 常量解出两段二进制表,其中一段用于
Runner.encrypt 的 algo2,另一段用于 algo3,通过
TryDecrypt.java 调用 Runner.encrypt
可验证哪一个表对应哪种行为
TryDecrypt.java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 import java.nio.ByteBuffer;import java.nio.ByteOrder;import java.nio.file.Files;import java.nio.file.Path;import java.security.MessageDigest;import java.util.Arrays;import java.util.List;public class TryDecrypt {private static final byte [] MAGIC = new byte [] {(byte )0x89 , 0x61 , 0x6c , 0x69 };private static final byte [] LZRR = new byte [] {0x4c , 0x5a , 0x52 , 0x52 };private static int u32le (byte [] b, int off) {return ByteBuffer.wrap(b, off, 4 )private static int indexOf (byte [] data, byte [] needle) {for (int i = 0 ; i <= data.length - needle.length; i++) {boolean ok = true ;for (int j = 0 ; j < needle.length; j++) {if (data[i + j] != needle[j]) {false ;break ;if (ok) return i;return -1 ;private static class Msg {int partIdx;int rsaLen;byte [] rsa;int fileCount;int [] offsets;byte [] payload;private static Msg parseMessage (byte [] data) throws Exception {int start = indexOf(data, MAGIC);if (start < 0 ) throw new IllegalArgumentException ("magic not found" );int partIdx = u32le(data, start + 4 );int rsaLen = u32le(data, start + 8 );int pos = start + 12 ;if (pos + rsaLen + 4 > data.length)throw new IllegalArgumentException ("bad rsa len" );byte [] rsa = Arrays.copyOfRange(data, pos, pos + rsaLen);int fileCount = u32le(data, pos);4 ;new String [fileCount];int [] offsets = new int [fileCount];for (int i = 0 ; i < fileCount; i++) {int nameLen = u32le(data, pos);4 ;byte [] nameX = Arrays.copyOfRange(data, pos, pos + nameLen);for (int j = 0 ; j < nameX.length; j++) {byte ) 233 ;new String (nameX, "UTF-8" );4 ;byte [] payload = Arrays.copyOfRange(data, pos, data.length);Msg m = new Msg ();return m;private static void trySeed (byte [] algo, byte [] payload, byte [] seed, String tag) {try {byte [] out = i.l.Runner.encrypt(algo, payload, seed);int pos = indexOf(out, LZRR);" " + tag + " -> outlen=" + out.length + " LZRR@" + pos);if (pos >= 0 ) {Path outPath = Path.of("dec_" + tag + ".bin" );" wrote " + outPath.toAbsolutePath());catch (Throwable t) {" " + tag + " -> failed: " ": " + t.getMessage());private static void probeSeedSensitivity (byte [] algo, byte [] payload) {byte [] baseSeed = new byte [8 ];byte [] baseOut = i.l.Runner.encrypt(algo, payload, baseSeed);byte [] basePrefix = Arrays.copyOf(baseOut, 8 );"seed sensitivity: basePrefix=" + bytesToHex(basePrefix));for (int idx = 0 ; idx < 8 ; idx++) {byte [] seed = new byte [8 ];1 ;byte [] out = i.l.Runner.encrypt(algo, payload, seed);byte [] pref = Arrays.copyOf(out, 8 );boolean same = Arrays.equals(basePrefix, pref);" seed[" + idx + "] samePrefix=" + same" prefix=" + bytesToHex(pref));private static String bytesToHex (byte [] b) {StringBuilder sb = new StringBuilder ();for (byte v : b) sb.append(String.format("%02x" , v));return sb.toString();public static void main (String[] args) throws Exception {"Working directory = " +"." ).toAbsolutePath().normalize());byte [] algo2 = Files.readAllBytes(Path.of("b64_0.bin" ));byte [] algo3 = Files.readAllBytes(Path.of("b64_1.bin" ));byte [] a10 = new byte [10 ];byte [] b20 = new byte [20 ];"len test: out1=" " out2=" "streams_py/127.0.0.1_61111-127.0.0.1_8889.bin" ,"streams_py/127.0.0.1_57692-127.0.0.1_8889.bin" ,"streams_py/127.0.0.1_52024-127.0.0.1_8889.bin" for (String p : streams) {byte [] data = Files.readAllBytes(Path.of(p));Msg m = parseMessage(data);"stream=" + p" part=" + m.partIdx" files=" + m.fileCount" payload=" + m.payload.length);byte [] rsa = m.rsa;byte [] rsaFirst8 = Arrays.copyOf(rsa, Math.min(8 , rsa.length));byte [] rsaLast8 = Arrays.copyOfRange(rsa,0 , rsa.length - 8 ), rsa.length);byte [] zeros8 = new byte [8 ];for (int a = 0 ; a < 2 ; a++) {byte [] algo = (a == 0 ) ? algo2 : algo3;String algoTag = (a == 0 ) ? "algo2" : "algo3" ;"part" + m.partIdx + "_" + algoTag + "_rsa" );"part" + m.partIdx + "_" + algoTag + "_rsaFirst8" );"part" + m.partIdx + "_" + algoTag + "_rsaLast8" );"part" + m.partIdx + "_" + algoTag + "_zeros8" );if (m.partIdx == 2 ) {"dec_part2_algo2_zeros.bin" ),"dec_part2_algo3_zeros.bin" ),byte [] seedFirst8 = Arrays.copyOf(rsa, 8 );byte [] seedLast8 = Arrays.copyOfRange(rsa, rsa.length - 8 , rsa.length);byte [] seedXor = new byte [8 ];for (int i = 0 ; i < 8 ; i++)byte )(seedFirst8[i] ^ seedLast8[i]);"part2_algo2_rsaFirst8" );"part2_algo2_rsaLast8" );"part2_algo2_rsaXor" );"MD5" ).digest(rsa),"part2_algo2_md5" );"SHA-1" ).digest(rsa),"part2_algo2_sha1" );"SHA-256" ).digest(rsa),"part2_algo2_sha256" );for (int si = 0 ; si < 8 ; si++) {for (int bit = 0 ; bit < 8 ; bit++) {byte [] seed = new byte [8 ];byte )(1 << bit);"dec_part2_algo2_seedb_" + si + "_" + bit + ".bin" ),
试验发现 algo3 与 seed 无关,任意 seed 输出一致,因此可视为对 payload
的固定变换;algo2 对 seed 的影响是线性 XOR,seed 64bit
每一位对应一个可叠加的差分输出
对于 part1 和 part3,用 algo3 解密对应 payload 即
Runner.encrypt(algo3, payload, seed) 直接得到 LZRR 压缩流,
依据 offsets 或按 LZRR 魔数切块逐一解压来还原 .java 与
Image1Part*.java
LZRR + RLE 解压
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 from __future__ import annotationsfrom pathlib import Pathfrom typing import Tuple import structb"LZRR" 0x0201 def parse_header (data: bytes ) -> Tuple [int , int , int , int , bytes ]:if len (data) < 16 :raise ValueError("data too short" )if data[:4 ] != MAGIC:raise ValueError("bad magic" )">H" , data[4 :6 ])[0 ]if ver != VERSION:raise ValueError(f"bad version: {ver} " )">H" , data[6 :8 ])[0 ]">I" , data[8 :12 ])[0 ]">I" , data[12 :16 ])[0 ]16 :]return flag, in_len, crc, ver, bodydef rle_decode (data: bytes ) -> bytes :bytearray ()0 len (data)while i < n:1 if b != 0xFF :continue if i >= n:raise ValueError("truncated RLE" )1 if cnt == 0xFF :0xFF )continue if i >= n:raise ValueError("truncated RLE value" )1 4 ))return bytes (out)class BitReader :def __init__ (self, data: bytes ) -> None :self .data = dataself .pos = 0 self .bit = 0 def read_bit (self ) -> int :if self .pos >= len (self .data):raise EOFError("bitstream exhausted" )self .data[self .pos]7 - self .bit)) & 1 self .bit += 1 if self .bit == 8 :self .bit = 0 self .pos += 1 return vdef read_bits (self, n: int ) -> int :0 for _ in range (n):1 ) | self .read_bit()return vdef lzrr_decompress (data: bytes ) -> bytes :if flag == 15 :elif flag != 13 :raise ValueError(f"unsupported flag: {flag} " )bytearray ()while len (out) < in_len:if tag == 0 :8 ))continue if br.read_bit() == 0 :8 )else :16 )if br.read_bit() == 0 :3 )else :if br.read_bit() == 0 :6 ) + 8 else :8 )3 if offset <= 0 :raise ValueError("invalid offset" )len (out) - offsetif start < 0 :raise ValueError("offset out of range" )for i in range (length):return bytes (out)def main () -> None :"dec_part1_algo3_rsa.bin" ),"dec_part3_algo3_rsa.bin" ),for p in inputs:".out" )print (f"{p.name} -> {out_path.name} ({len (out)} bytes)" )if __name__ == "__main__" :
恢复 part1/part3 的 .java
与图片段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 from __future__ import annotationsfrom pathlib import Pathimport structimport reimport lzrr_decompress as lzb"\x89ali" def parse_message (data: bytes ):if start < 0 :raise ValueError("magic not found" )"<I" , data, start + 4 )[0 ]"<I" , data, start + 8 )[0 ]12 + rsa_len"<I" , data, pos)[0 ]4 for _ in range (file_count):"<I" , data, pos)[0 ]4 bytes (b ^ 233 for b in name_x).decode("utf-8" , errors="replace" )"<I" , data, pos)[0 ]4 return part_idx, files, offsetsdef split_lzrr_blocks (payload: bytes ) -> list [bytes ]:b"LZRR" for i in range (len (payload) - 3 ) if payload[i:i + 4 ] == magic]for i, start in enumerate (positions):1 ] if i + 1 < len (positions) else len (payload)return blocksdef recover (part_stream: Path, dec_payload: Path, out_dir: Path ) -> None :if len (blocks) != len (files):print (f"part{part_idx} : block count {len (blocks)} != file count {len (files)} " )True , exist_ok=True )for idx, block in enumerate (blocks):if idx < len (files) else f"file_{idx} .bin" True , exist_ok=True )print (f"part{part_idx} : wrote {dest} ({len (out)} bytes)" )def search_flag (root: Path ) -> None :for p in root.rglob("*" ):if p.is_file():rb"alictf\{[^}]{0,200}\}" , b)if m:print ("flag" , m.group(0 ).decode("ascii" , errors="ignore" ), "in" , p)def main () -> None :"." )"streams_py" / "127.0.0.1_61111-127.0.0.1_8889.bin" ,"dec_part1_algo3_rsa.bin" ,"recovered" / "part1" ,"streams_py" / "127.0.0.1_52024-127.0.0.1_8889.bin" ,"dec_part3_algo3_rsa.bin" ,"recovered" / "part3" ,"recovered" )if __name__ == "__main__" :
恢复 part2 的 .java 与图片段
对于 part2,先用 seed=0 得到
dec_part2_algo2_zeros.bin,再对 seed 64
位逐位置 1,生成 64 个基向量输出
dec_part2_algo2_seedb_{si}_{bit}.bin,利用 LZRR
头 8 字节已知模式 LZRR 0201 flag 建立 GF(2) 线性方程组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 from __future__ import annotationsfrom pathlib import Pathimport structimport reimport lzrr_decompress as lzb"\x89ali" def parse_message (path: Path ):if start < 0 :raise ValueError("magic not found" )"<I" , data, start + 8 )[0 ]12 + rsa_len"<I" , data, pos)[0 ]4 for _ in range (file_count):"<I" , data, pos)[0 ]4 bytes (b ^ 233 for b in name_x).decode("utf-8" , errors="replace" )"<I" , data, pos)[0 ]4 return files, offsetsdef build_equations (base: bytes , deltas: list [bytes ], offsets: list [int ], flags: list [int ] ):for off, flag in zip (offsets, flags):b"LZRR" + b"\x02\x01" + struct.pack(">H" , flag)for i in range (8 ):for bit in range (8 ):1 0 for j in range (64 ):if ((deltas[j][off + i] >> bit) & 1 ) != 0 :1 << j)return eq_masks, eq_rhsdef solve_linear (eq_masks: list [int ], eq_rhs: list [int ] ) -> int | None :list (zip (eq_masks, eq_rhs))for mask, rhs in rows:while m != 0 :1 )if bit in pivots:0 ]1 ]else :break if m == 0 and r == 1 :return None 0 for bit in sorted (pivots.keys(), reverse=True ):bin (known).count("1" ) & 1 if val:1 << bit)return soldef apply_seed (base: bytes , deltas: list [bytes ], seed_bits: int ) -> bytes :bytearray (base)for j in range (64 ):if (seed_bits >> j) & 1 :bytearray (b ^ d for b, d in zip (out, dj))return bytes (out)def main () -> None :"streams_py" / "127.0.0.1_57692-127.0.0.1_8889.bin" "dec_part2_algo2_zeros.bin" list [bytes ] = []for si in range (8 ):for bit in range (8 ):f"dec_part2_algo2_seedb_{si} _{bit} .bin" bytes (b ^ s for b, s in zip (base, data))13 , 15 ]None for f0 in flags_list:for f1 in flags_list:for f2 in flags_list:if seed_bits is None :continue True for off, flag in zip (offsets, flags):8 ]if header != (b"LZRR" + b"\x02\x01" + struct.pack(">H" , flag)):False break if ok:break if found:break if found:break if not found:print ("no seed found" )return 8 , "little" )print ("seed" , seed_bytes.hex (), "flags" , flags)"dec_part2_algo2_seed.bin" "recovered" / "part2" True , exist_ok=True )for idx, off in enumerate (offsets):1 ] if idx + 1 < len (offsets) else len (out)True , exist_ok=True )print ("wrote" , dest)for p in out_dir.rglob("*.java" ):rb"alictf\{[^}]{0,200}\}" , p.read_bytes())if m:print ("flag" , m.group(0 ).decode("ascii" , errors="ignore" ), "in" , p)if __name__ == "__main__" :
解得 seed 为 a91b1bb4e8978bda,然后合成真实
payload 并解压得到 .java 与
Image1Part*.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 from __future__ import annotationsfrom pathlib import Pathimport reimport structimport lzrr_decompress as lzb"\x89ali" def parse_message (data: bytes ):if start < 0 :raise ValueError("magic not found" )"<I" , data, start + 4 )[0 ]"<I" , data, start + 8 )[0 ]12 + rsa_len"<I" , data, pos)[0 ]4 for _ in range (file_count):"<I" , data, pos)[0 ]4 bytes (b ^ 233 for b in name_x).decode("utf-8" , errors="replace" )"<I" , data, pos)[0 ]4 return part_idx, files, offsetsdef split_lzrr_blocks (payload: bytes ) -> list [bytes ]:b"LZRR" for i in range (len (payload) - 3 ) if payload[i:i + 4 ] == magic]for i, start in enumerate (positions):1 ] if i + 1 < len (positions) else len (payload)return blocksdef recover (part_stream: Path, dec_payload: Path, out_dir: Path ) -> None :True , exist_ok=True )for idx, block in enumerate (blocks):if idx < len (files) else f"file_{idx} .bin" True , exist_ok=True )if dest.suffix == ".java" :print (f"part{part_idx} : {dest.relative_to(out_dir).as_posix()} " )def main () -> None :"streams_py" / "127.0.0.1_61111-127.0.0.1_8889.bin" ,"dec_part1_algo3_rsa.bin" ,"recovered" / "part1" ,"streams_py" / "127.0.0.1_57692-127.0.0.1_8889.bin" ,"dec_part2_algo2_seed.bin" ,"recovered" / "part2" ,"streams_py" / "127.0.0.1_52024-127.0.0.1_8889.bin" ,"dec_part3_algo3_rsa.bin" ,"recovered" / "part3" ,if __name__ == "__main__" :
图片合成
最后从 Image1Part*.java 抽取 base64 ,生成
part1..6.jpg,再横向拼接成 combined.jpg
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from __future__ import annotationsfrom pathlib import Pathimport base64import redef extract_images (recovered_root: Path, out_dir: Path ) -> list [Path]:True , exist_ok=True )list [Path] = []for java_path in recovered_root.rglob("Image1Part*.java" ):"utf-8" , errors="ignore" )r"Image1Part(\d+)" , java_path.name)r'IMAGE_DATA\s*=\s*"([A-Za-z0-9+/=]+)"' , text)if not (m and m2):continue int (m.group(1 ))1 ))f"part{part_no} .jpg" return sorted (out_paths, key=lambda p: int (re.search(r"part(\d+)" , p.name).group(1 )))def combine_images (paths: list [Path], out_path: Path ) -> Path | None :try :from PIL import Imageexcept Exception as exc:print (f"PIL not available: {exc} " )return None open (p) for p in paths]zip (*(im.size for im in imgs))sum (widths)max (heights)"RGB" , (total_width, max_height))0 for im in imgs:0 ))0 ]return out_pathdef main () -> None :"recovered" "images" if not parts:print ("no image parts extracted" )return "combined.jpg" )if out:print (f"combined image -> {out} " )if __name__ == "__main__" :
OCR 识别一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from pathlib import Pathimport numpy as npimport cv2import easyocr'recovered' / 'images' / 'combined.jpg' def get_boxes (bin_img ):for c in cnts:if area < 1000 :continue if wc > 0.95 * w and hc > 0.95 * h:continue lambda t: t[4 ], reverse=True )return boxes255 ,35 ,10 'en' ], gpu=False )'abcdefABCDEF0123456789-{}' for i, (x, y, wc, hc, area) in enumerate (boxes[:5 ]):None , fx=2 , fy=2 , interpolation=cv2.INTER_CUBIC)for _, t, c in res]print (i, (x, y, wc, hc), texts)
flag 为 alictf{5a8e0fb1-d3f5-4b13-8424-164faab9bbd2}