xhs shield 参数分析
断断续续其实拖了挺长时间的,本意是想通过亲手实践来学一下逆 app 的参数是一个怎样的流程,顺便了解下实战中涉及的安卓逆向的知识
定位 so
抓包分析
用 Reqable 对 xhs 进行抓包,翻了下请求,在请求头里看到了 shield 参数,一共 134 个字符
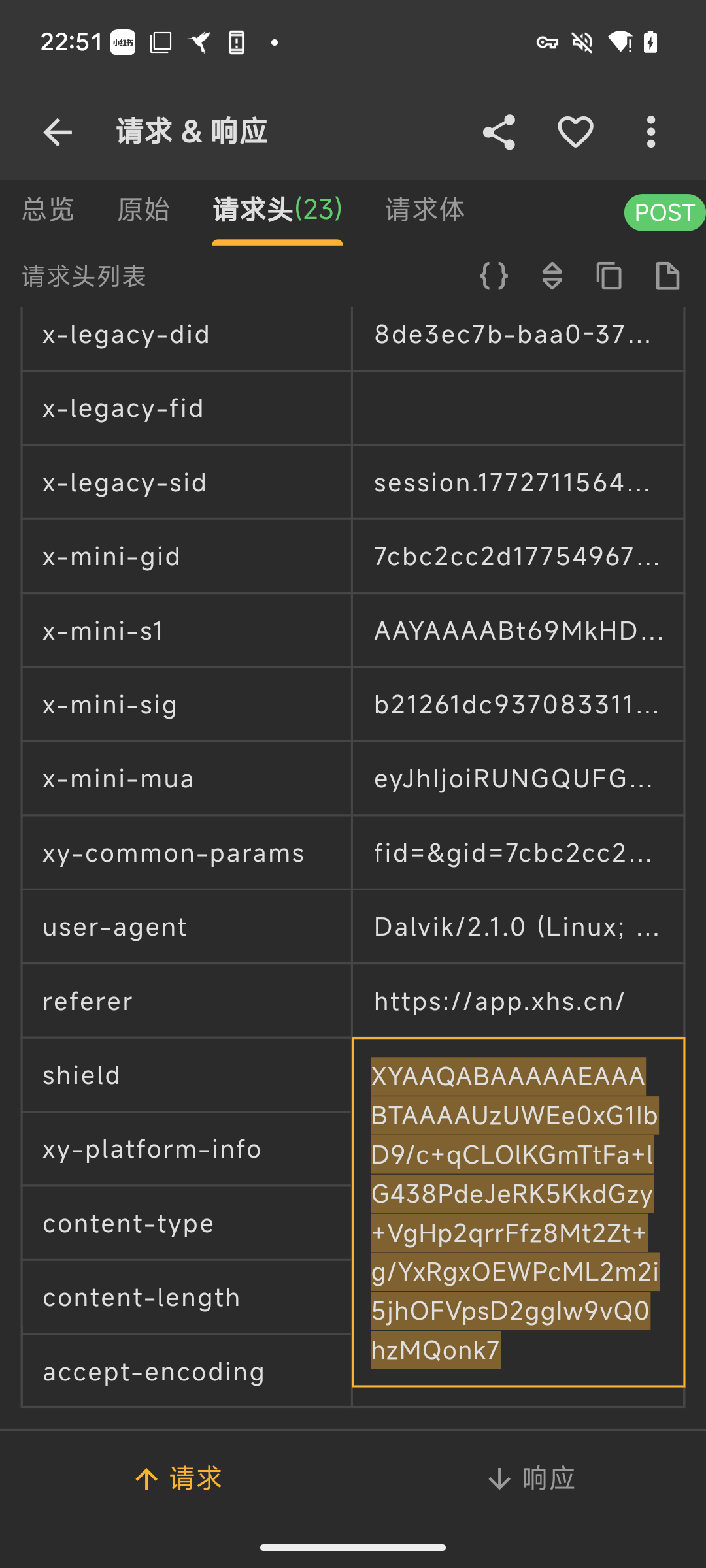
多观察几个请求头的这个参数可以发现它前 112 个字符是一样的,后面 22 个字符是变化的
hook NewStringUTF
首先需要知道这个这一串参数是从什么地方生成的,一般思路是 hook NewStringUTF
NewStringUTF是 JNI 中的一个函数,把 native 层的const char *字符串转成 Java 层的jstring,相当于 Java/Kotlin 和 C/C++ native 代码之间的桥梁
JNI 规范里的 NewStringUTF 原型是:
1 | |
它会根据传入的 bytes 构造一个新的 java.lang.String, 并且它在 JNIEnv 函数表里的索引是 167
由此可以写出 hook NewStringUTF 的 frida 脚本
1 | |
但是尝试之后直接 Process terminated 了
开始以为是 frida 检测,绕了半天也没用,后面发现不是检测的问题,而是 hook 时机太早了,延后一点再注入这个就能正常看到日志了
1 | |
由此可以定位到要分析的参数在 libxyass.so 中
样本的是从 Google Play 下载的,因为谷歌推行了
Android App Bundle(.abb),按设备下发 apk,lib 在 apks 解压后的split_config.arm64_v8a.apk中
分析 so
sub_46DB0
根据 call off 的地址在 libxyass.so 中定位
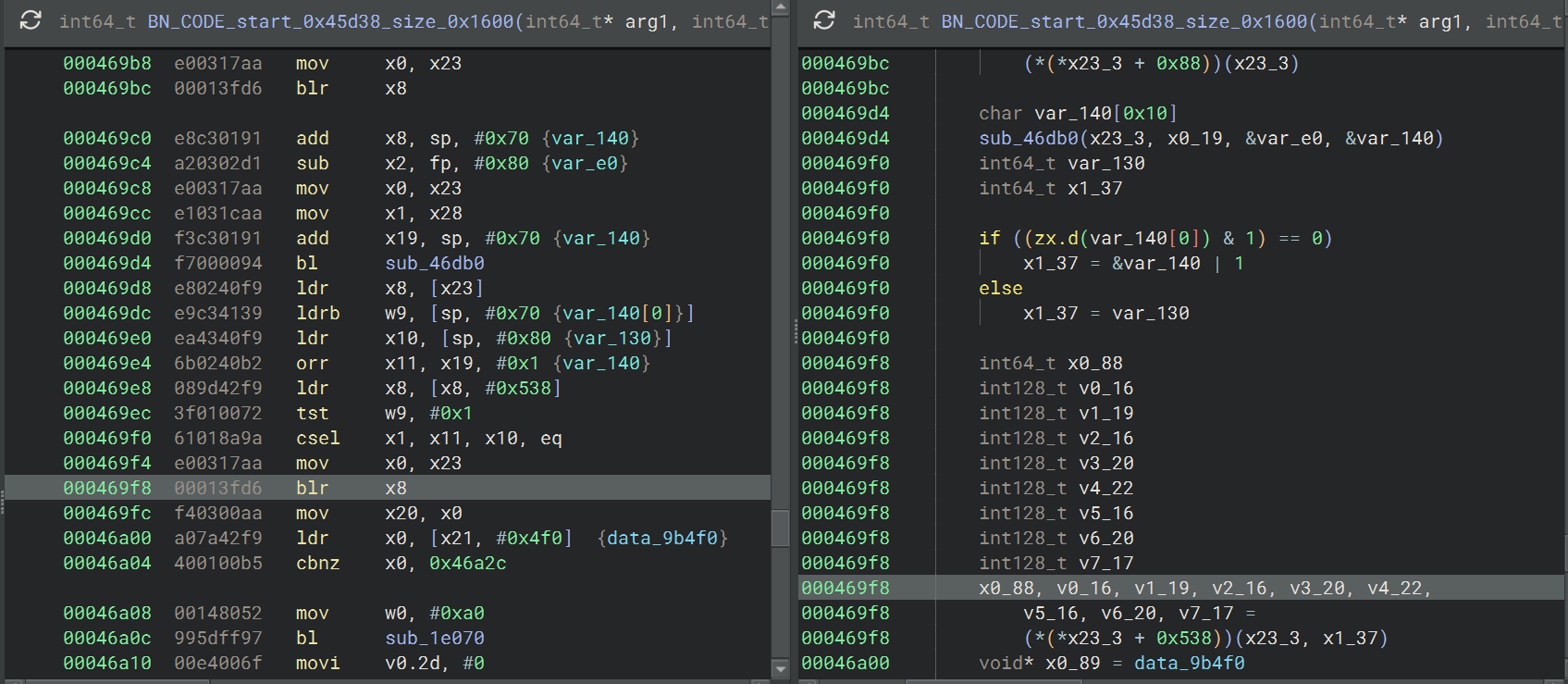
caller off 拿到的是 return address,也就是 NewStringUTF 调完之后,要返回到的下一条指令地址,想要拿到调用地址的偏移需要减去 4 字节指令长度,所以调用地址的偏移是 0x469f8
而往前看最近的函数 sub_46DB0 可能就是构造这个参数的函数了
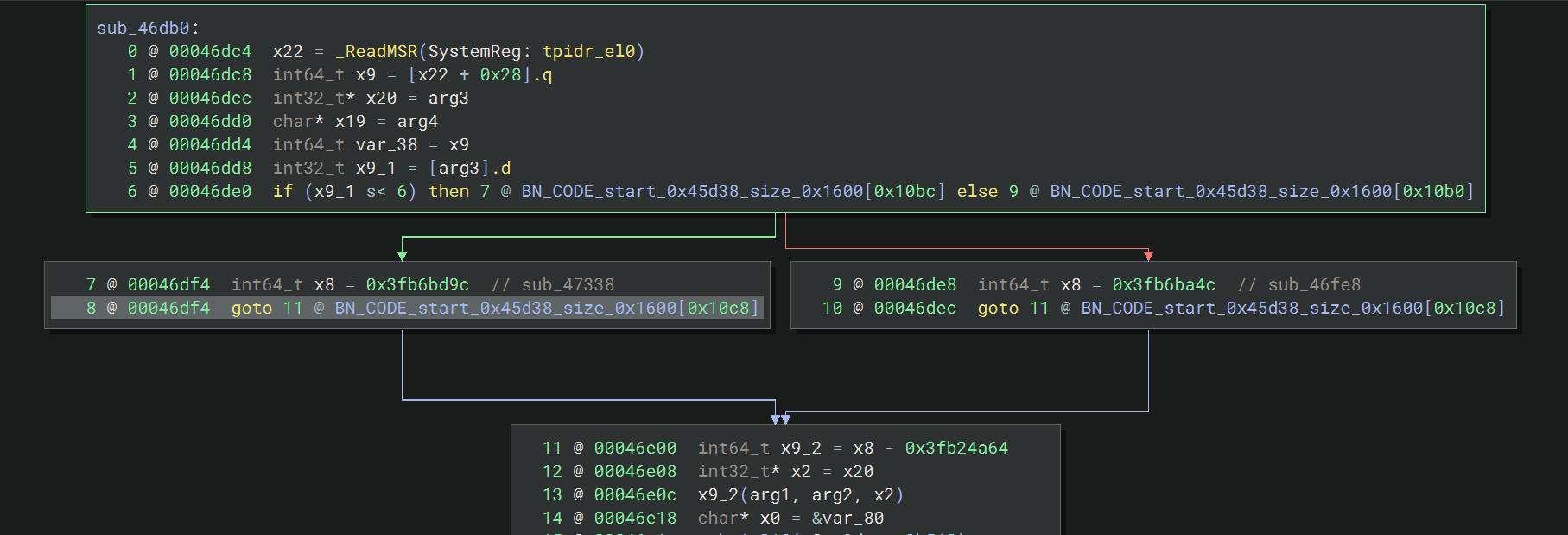
先是判断一个参数(怀疑是版本) 是否小于 6,根据结果选择 sub_47338 或者 sub_46fe8 这两个分支
hook 下 sub_46DB0 函数的参数
1 | |
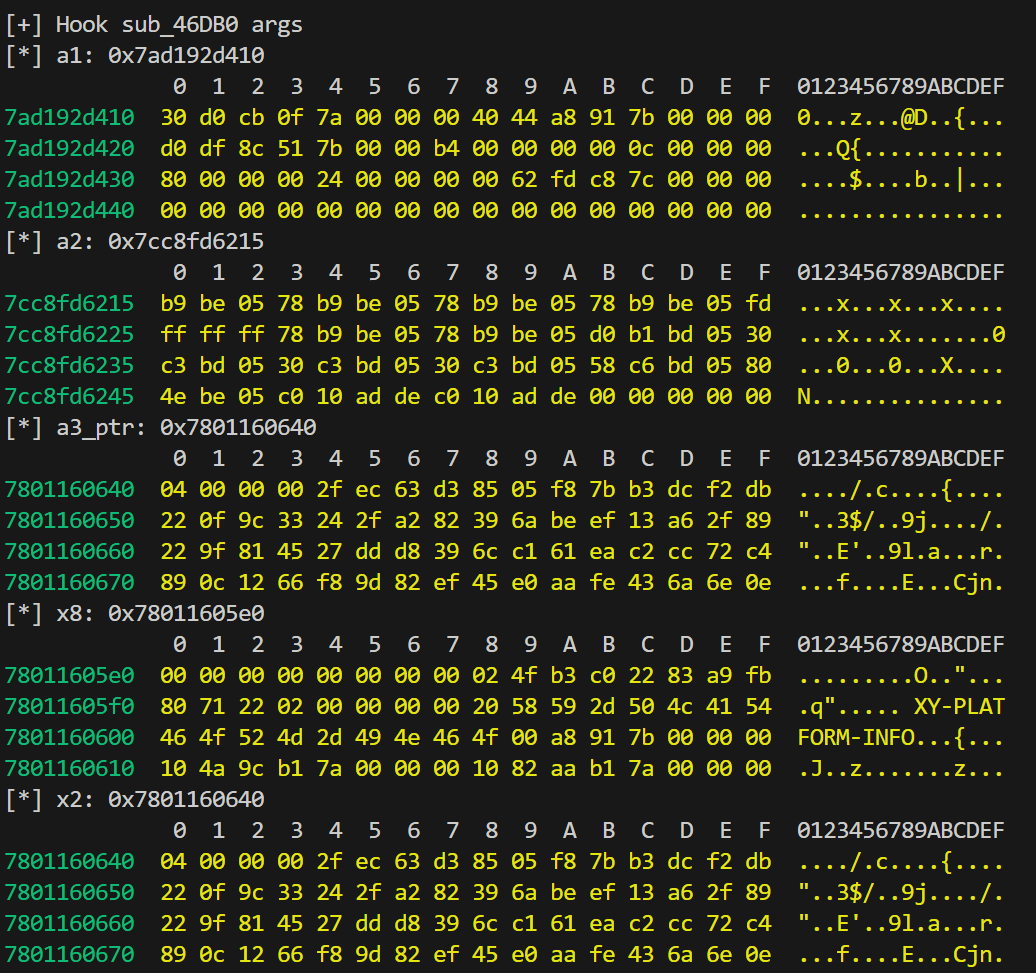
从 arg3 指向的地址处看到第一个字节是 0x4,4 < 6, 所以走的是 sub_47338 分支
1 | |
sub_4b8c8(RC4 + Base64)
Base64
可以看到这个函数有很多个参数并且最后面有个明显的 base64
算输出长度
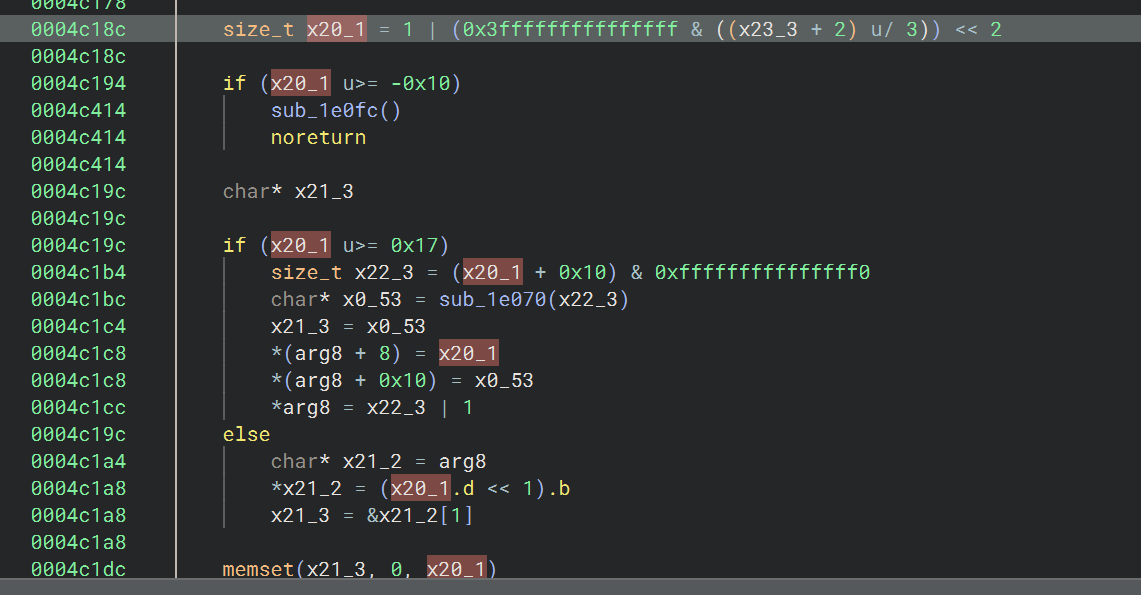
Base64 字符表
sub_1e3c8
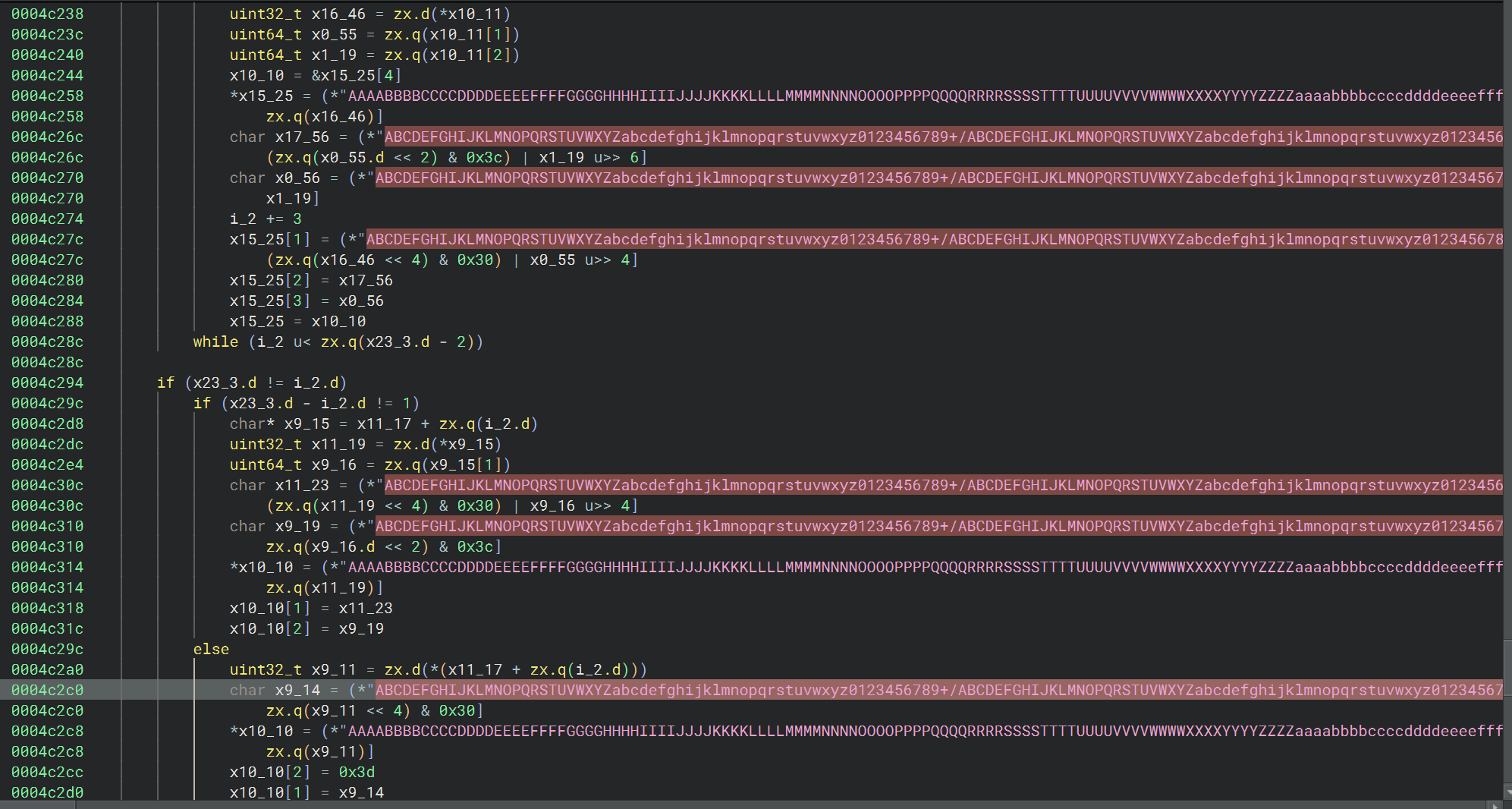
sub_4b8c8 中多次调用的这个函数
1 | |
arg1:目标字符串对象,arg2:要追加的数据地址,arg3:要追加的数据长度
先判断 arg1 当前是短模式还是长模式,取出当前长度 size 和当前容量 capacity,判断剩余容量够不够追加 arg3 字节,够的话直接把 arg2 指向的数据复制到末尾,不够的话调用 sub_1e1d4 做扩容并追加,然后更新长度字段,在新末尾补 '\0',返回 arg1
就是 append string 的逻辑
sub_1e070
1 | |
相当于 C++ 里的 operator new(size_t) / allocator 的底层分配函数
sub_1e494
1 | |
从位置 arg2 开始删除最多 arg3 个字符,并维护结尾 \0
结合反编译先 hook 一下参数
1 | |
部分日志如下
1 | |
9193803 是版本号,a7 恒为 16,推测为 a6 的长度,a6 的 16 字节没什么规律,应该是经过某个加密后的数据
结合 ai 分析修缮了下 hook 脚本,把返回值顺便也 hook 出来
1 | |
1 | |
RC4
中间部分很像 RC4
初始化 256 字节状态表
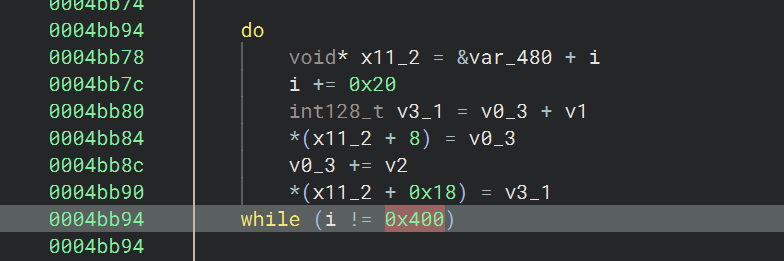
之后是 KSA ,key 为 std::abort();
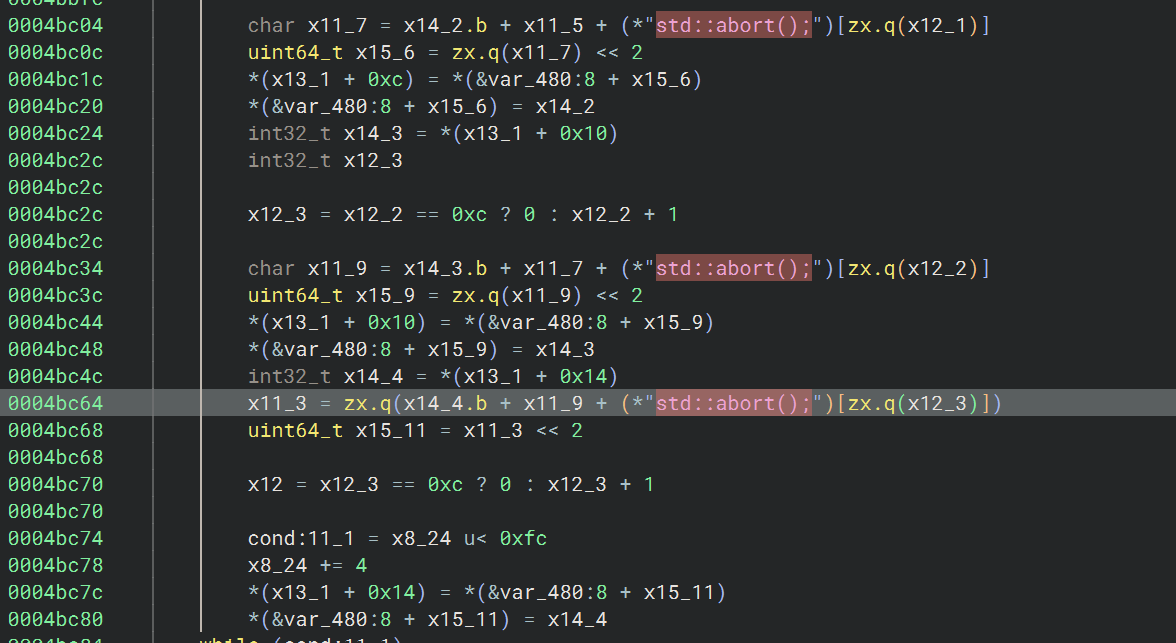
这个 key 通过 frida hook 也能验证
1 | |
hook 结果
1 | |
后面的循环则是 PRGA + XOR 输出,在循环里面更新索引,从状态表取值,swap,再取一个字节与明文异或
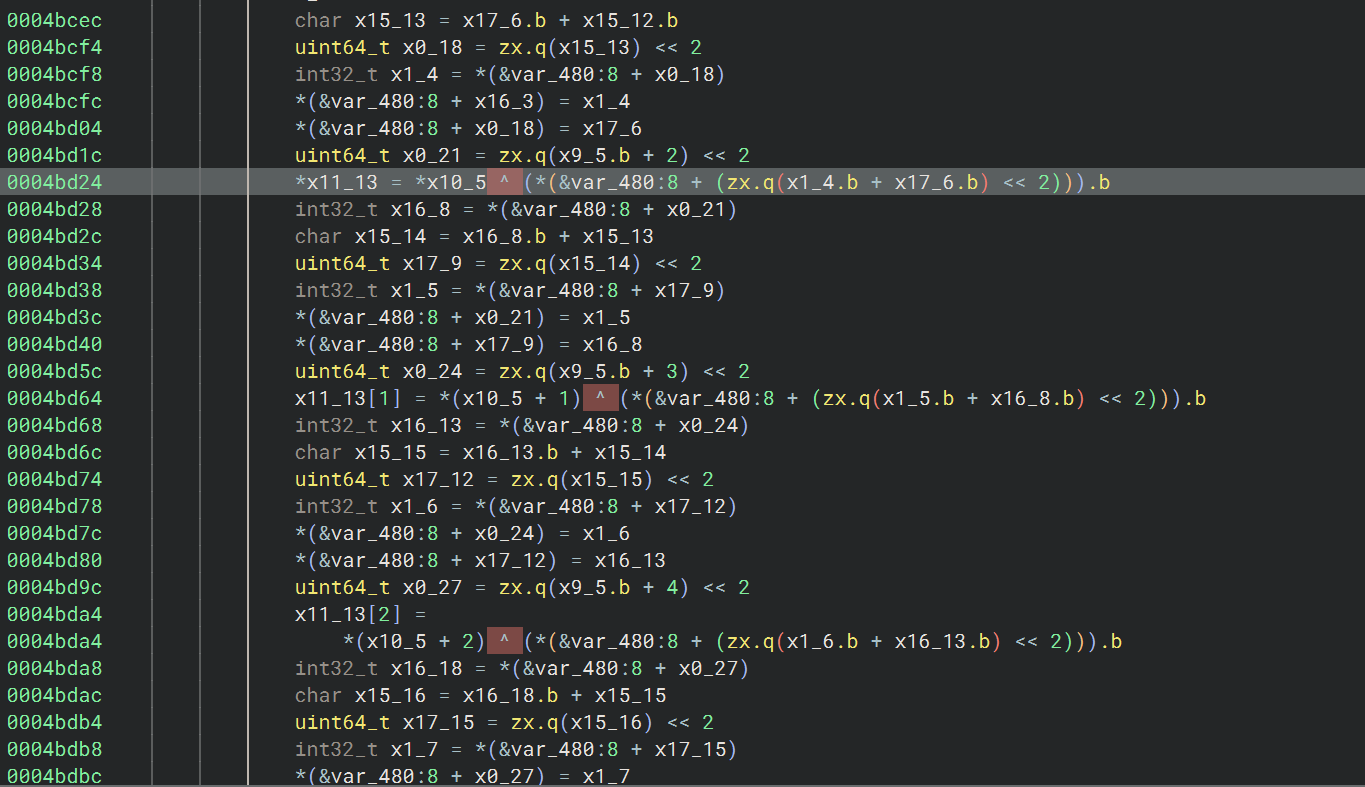
hook append 函数(sub_1e3c8)
这个 hook 确实是挺重要的一个 hook,很多推测和验证都是根据这个 hook 拿到的数据来分析的
1 | |
这是其中一轮的日志
1 | |
根据这个结果可以看出,它先加载了 24 字节的数据,接着是版本号 9193803,然后是一个 UUID 8de3ec7b-baa0-375f-bd3f-006dd6b65325,最后是 16 字节的加密数据,到这里一共有 83 字节的数据,经过了 RC4 加密,加密后又追加了 16 字节的数据,最后对 99 字节的数据进行了 Base64 编码
并且可以验证这个 RC4 是标准的
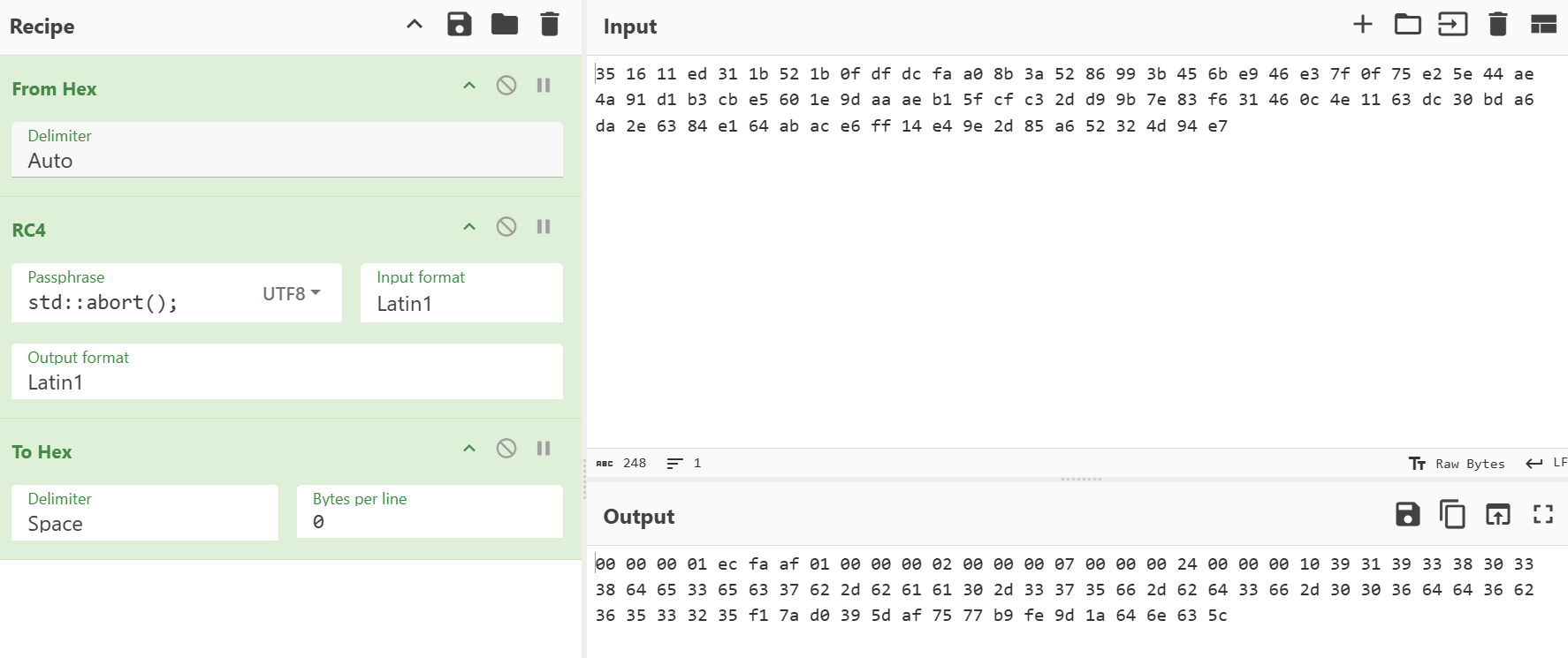
观察多轮结果可以发现 RC4 结束后 append 的那 16 字节数据是固定的 00 04 00 04 00 00 00 01 00 00 00 53 00 00 00 53,变化的是进入 RC4 加密前的 16 字节
而对于最开始加载的 24 字节的 Header 其实是与参数相对应的
00 00 00 01 是 arg1 的大端表示
ec fa af 01 是 arg3 的大端表示

00 00 00 02
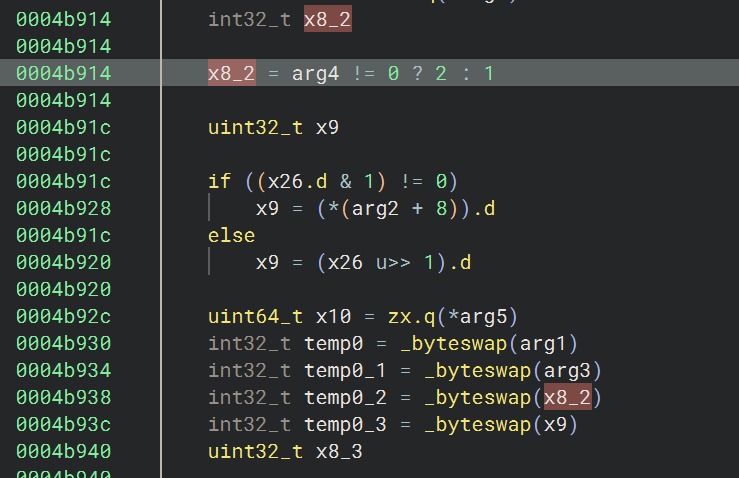
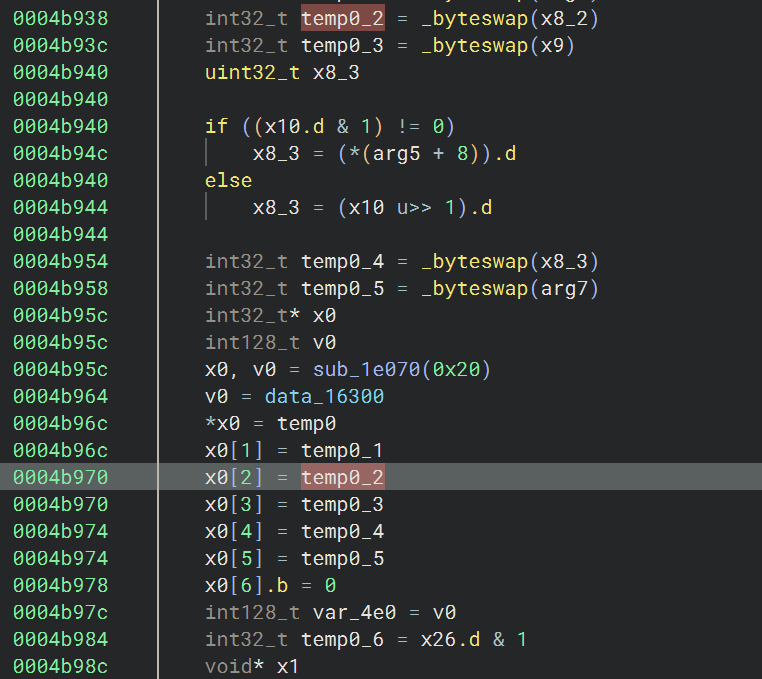
arg4 != 0 所以转换为 Header 中的 2
00 00 00 07 是 arg2 的长度(即版本号字符串 9193803 的长度)
00 00 00 24 是 arg5 的长度(即 UUID 字符串的长度)
00 00 00 10 是 arg6 的长度
sub_47338
分析这条链路的时候,有很多 br 间接跳转和混淆
把 Sections 中的 .data 由默认的可写改为只读,这样能解决一部分简单的间接跳转,bn 可以自动分析出来跳转地址
另外的间接跳转则要根据不同情况进行分析
1 | |
sub_850d8
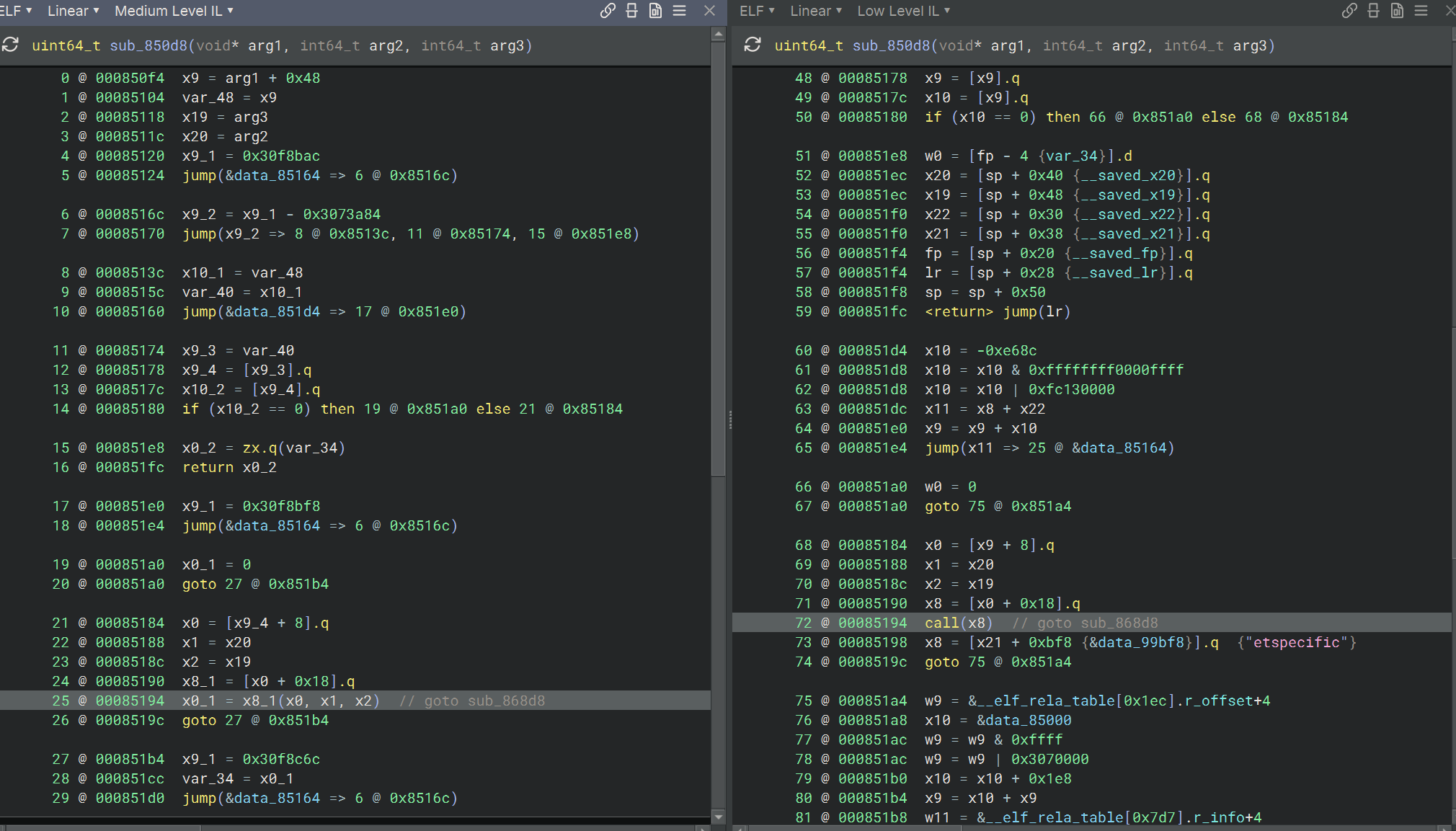
虚函数调用,frida hook 或者 trace 的方式可以获取到 vtable 和函数偏移,得到的 0x85194 处调用的 function_offset 是 0x868d8,所以是 sub_868d8(x0, arg2, arg3)
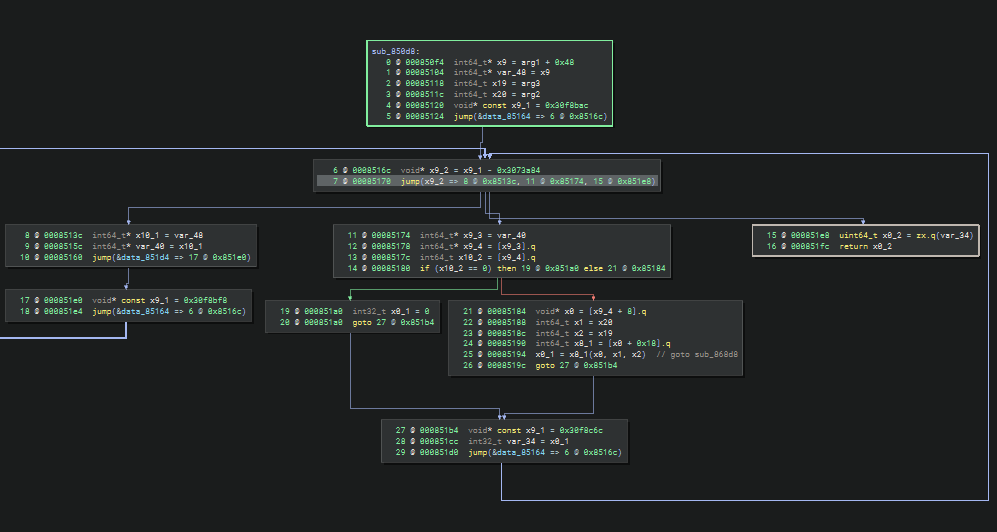
同时这个函数也是一个小型的控制流平坦化,分发器通过 x9_2 的值来决定下一步执行的基本块
sub_868a8
0x868d8 跳转过去实际是在 sub_868a8 这个函数里面
1 | |
很像是一个 hash update 的函数 Update(ctx, data, len)
根据反编译函数签名可以分析为 sub_868a8(ctx_wrapper* arg1, const uint8_t* data, size_t len)
arg1 是 外层对象, *(arg1 + 0x10) 是 hash context 结构体,arg2 是输入数据指针,arg3 是输入长度
sub_86e44
这个函数中由多个条件语句控制的间接跳转,修复好跳转后发现是嵌套了多层控制流平坦化的函数
详细分析见 BN IL 层解决多条件控制的双分支间接跳转
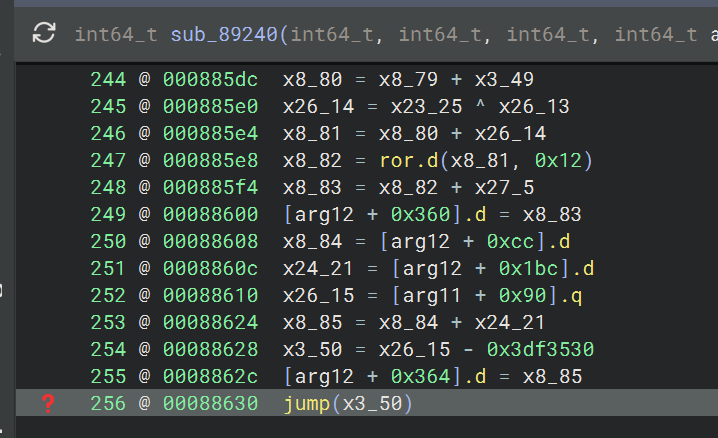
sub_89240
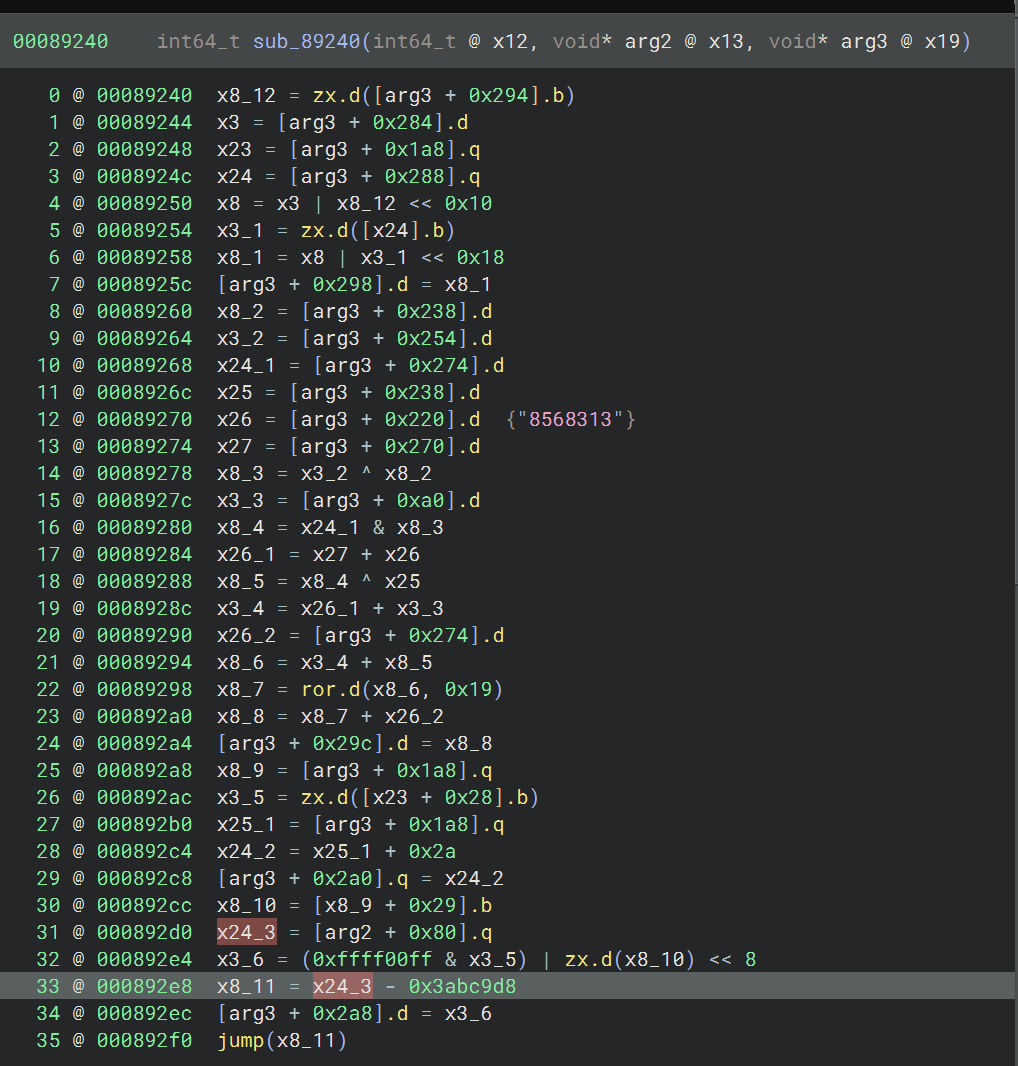
另外这个 so 里面还出现了不少这种结构的跳转,从 jump 往前分析可以看到,如果要计算最终的跳转地址,需要得到参数值,如果只是处理单个函数的这种结构的间接跳转的话,可以直接 frida hook 获取参数值获得地址,然后从地址中读值,就能计算出最后的跳转地址了,算出之后在 bn 的 mlil 层用 Set User Variable Value 的方式设置成 ConstantValue 填入计算出的固定值,bn 就能接着往下分析了
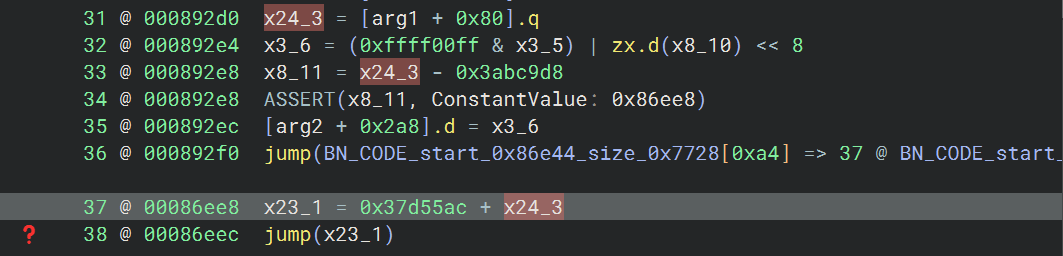
设置完之后发现又有新的跳转,并且跳转地址计算依赖于上次计算也同样涉及得到的 x24_3,那就直接给 x24_3 设置成算出的常量值
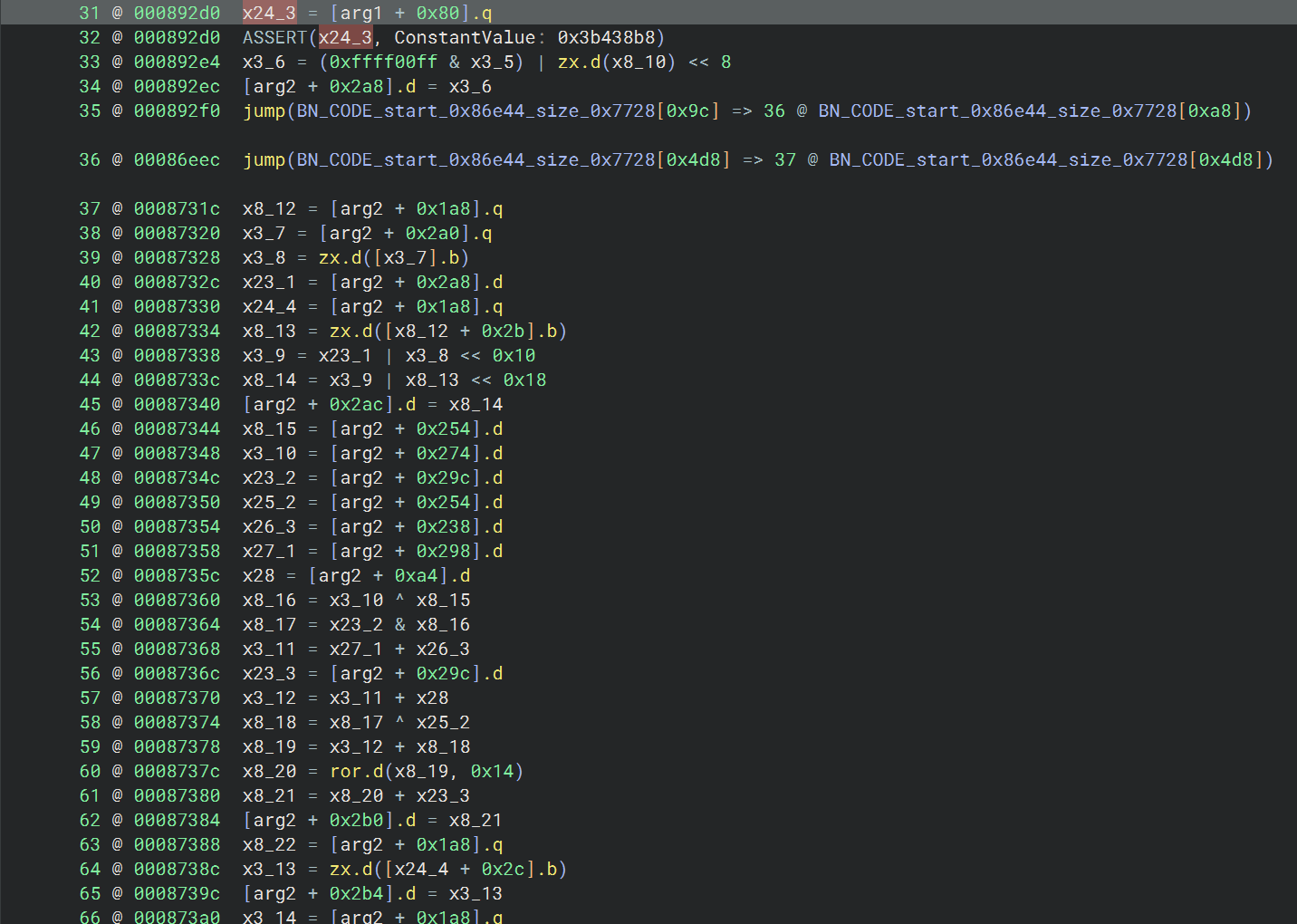
这样的话 bn 就能顺利分析下去了,并且下方出现了新的类似的跳转结构

在分析的过程中发现样本中有很多都是这样的结构,每次都改 frida 脚本和手动指定值很麻烦,于是考虑自动化实现这个过程
首先在 bn 中识别出这种跳转结构,并且收集计算跳转地址和进行 frida hook 所需要的所有数据,然后自动生成 frida 脚本,执行 hook 后,再用脚本批量赋值的方式给所有这种结构的跳转设置跳转地址
因为处理混淆的过程中先处理的这种跳转结构,再去处理的前面那种由多个条件语句控制的间接跳转,所以当时没有意识到这些结构就是被控制流平坦化打乱的一个个块
而在另一个函数中能明显的看出来
sub_886d0
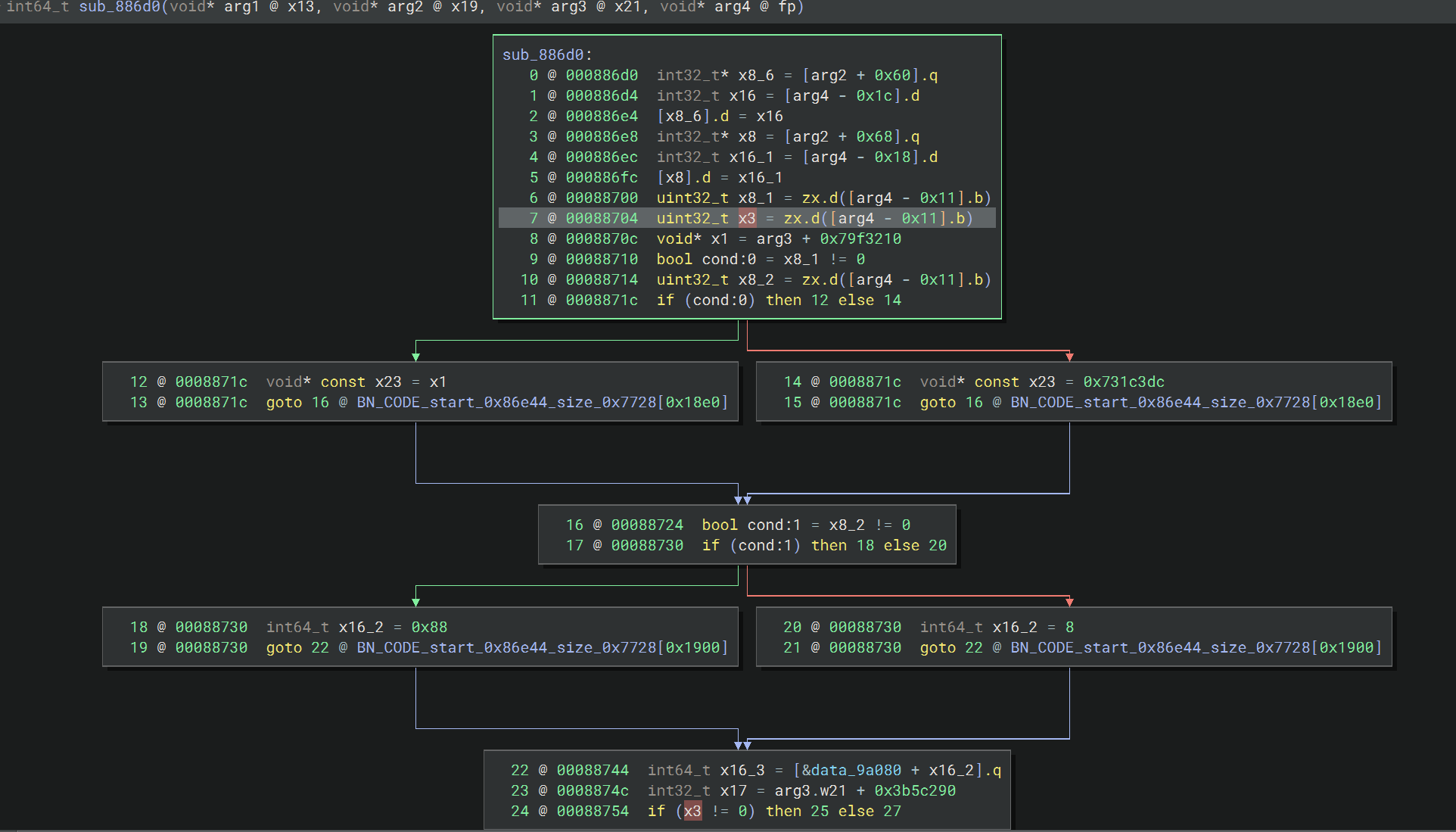
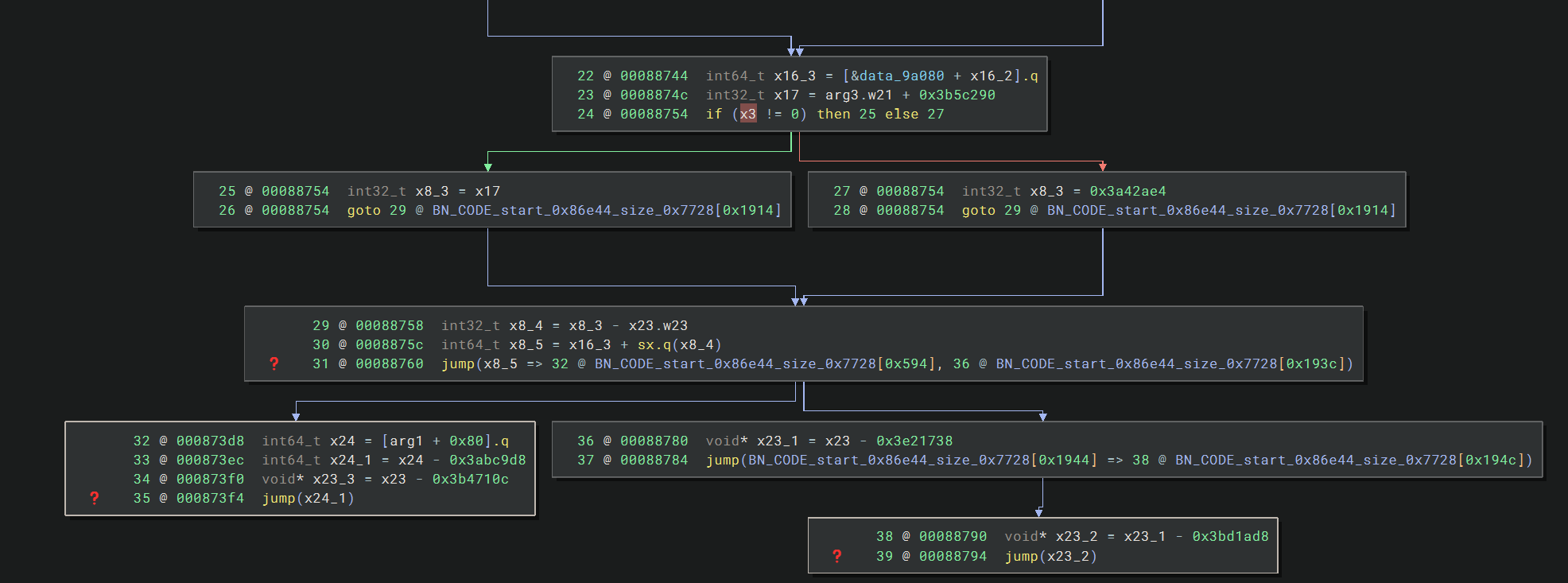
这个函数和上面 sub_86e44 的混淆模式很像,虽然有三个条件,但是依旧在本质上是相同的 cond,而且最后的两个未解析出来的 jump 正是上面那些间接跳转块的结构
不同的是,这个函数有关地址的计算用到了传入的参数,这就对静态分析造成了很大的影响(其实最开始 bn 连 0x88760 处跳转的两个地址都没有算出来,图上能分析出来是手动指定过的),用解决 sub_86e44 方式就处理不了了,因为能解析出跳转地址的前提是能收集到所有计算需要的数据,而这个函数多处计算缺乏 arg 值,所以只能结合动态 hook 的结果来分析
一共进行三个步骤:bn 中识别结构准备 hook 所需数据 -> frida hook 收集 patch 数据 -> bn 中批量设置跳转地址
自动化收集数据
以 0x873f4 处的跳转为例,要求 x24_1 的值,需要 x24 的值和后面的常量,x24 的值依赖于 arg1
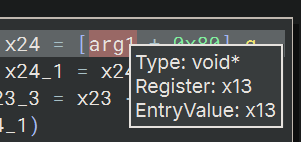
arg1 对应寄存器 x13,后续也直接收集对应的寄存器名字
所以第一个 bn 自动化脚本要做的事就是扫描所有函数,识别出该种结构的跳转,获取 jump 地址,jump 值 x24_1 定义处地址,收集常量 0x3abc9d8、算 x24 用到的寄存器 x13,偏移量为 0x80,同时关注从地址中读取的数据大小以及这个数据与常量的运算方式(因为可能在 mlil 层看到的是减去一个常量但实际是 add 操作加上一个负数,所以对这两种模式都作了匹配)
对 so 中所有函数进行上述操作,获得这些信息之后直接生成相应的 frida 脚本,就不用每次去手动修改 hook 代码了
1 | |
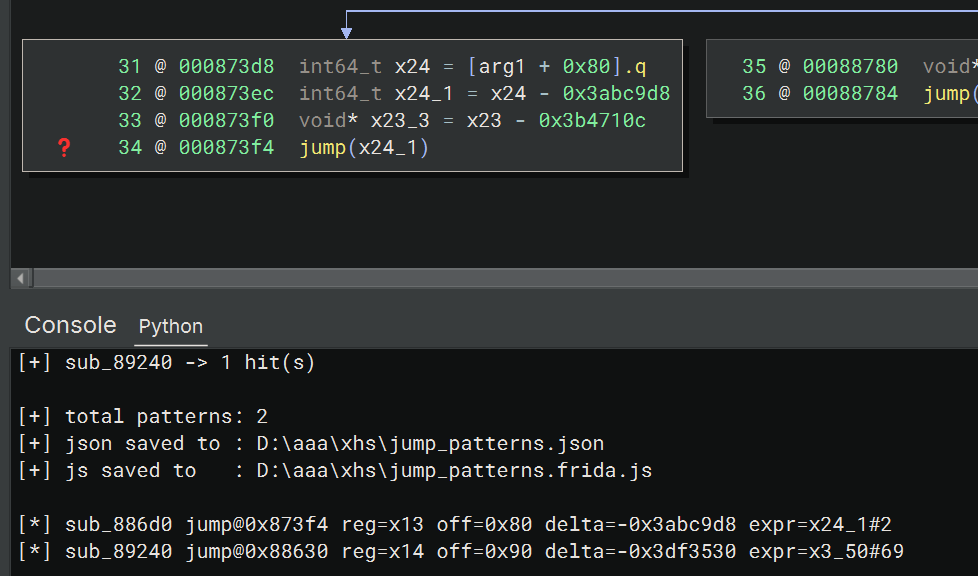
可以看到 bn 成功识别出了结构匹配的跳转
frida hook
使用上一步生成的 frida 脚本进行 hook 操作,这里写了一个 python 脚本来执行 frida,因为直接在控制台打印日志太多太频繁了不方便查看,所以改成通过 send 的方式把数据发送回 python 脚本,由 python 来处理日志输出,同时可以生成两份格式的文件,一份便于自己阅读查看,一份便于后续写 bn python 脚本时读取内容来批量设置跳转地址
上面例子得到的 frida 脚本
1 | |
python 交互
1 | |
hook 结果
1 | |
批量设置跳转地址
hook 日志中有大量重复的内容,为了防止 patch 时重复设置值,读取 .jsonl 文件的记录后先按 (jump_off, target_off) 去重
核心 patch 用到了 set_user_var_value(var, definition_site, value) 这个 api,在 mlil 层批量设置指定的跳转地址
1 | |
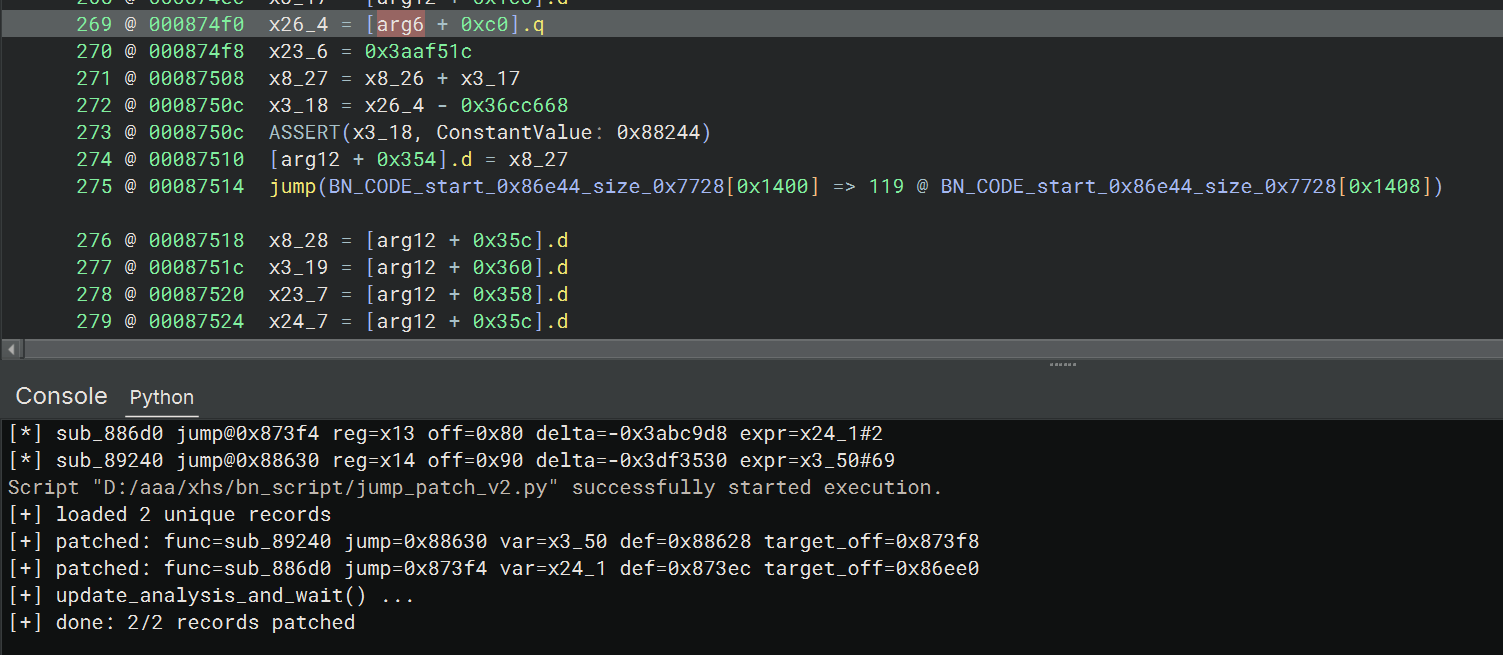
成功设置 patch
需要注意的是,每次修好一个跳转后,bn 可能会分析出新的跳转,所以上面的操作需要多次执行,直到没有新的跳转结构被识别出来为止
后续遇到不同的跳转结构就修改识别规则,重复上面的流程
sub_89240
这个函数就是按照上面的步骤能够完全将间接跳转修好的,修好之后能看出它是被控制流平坦化了的
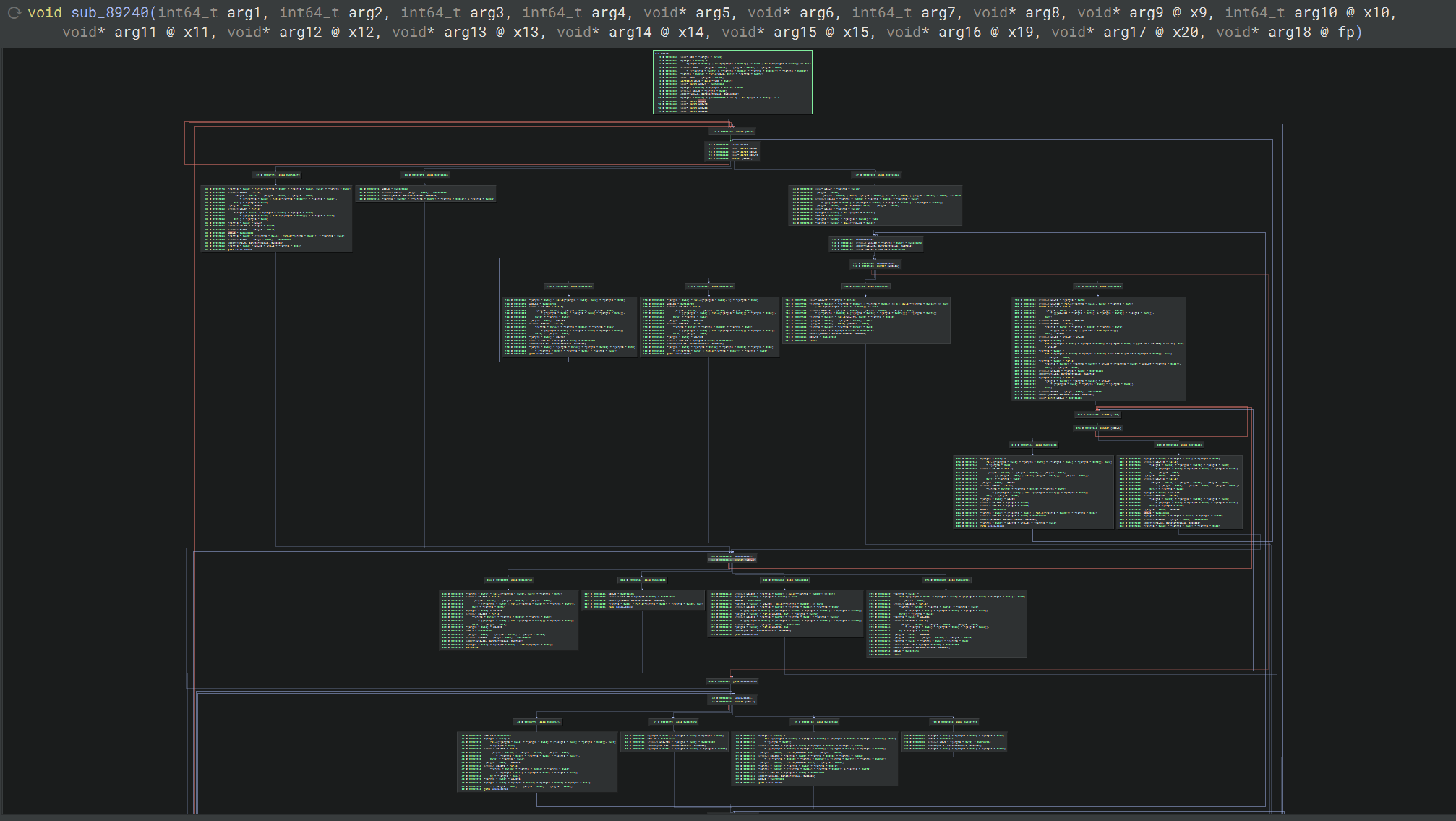
而且也是有多个分发器相互嵌套的
HMAC-MD5
把这条链路的间接跳转大致全部修好之后,通过反编译的内容结合 hook 分析出这是一个 HMAC-MD5 实现
1 | |
贴一小段 hook 结果
1 | |
比对后可知 hook 得到的最后的 digest 就是在最前面的 RC4 中未知的那 16 字节
观察这个输出的前两个块,它们逐字节异或得到的全是 0x6a,而 HMAC 中的两个固定常量 ipad(0x36) 和 opad(0x5c) 相互异或的结果正好是 0x6a,加之这两个块在 hook 日志中重复出现,基本可以确定这两个块是 A = K ⊕ ipad,B = K ⊕ opad,但是问题又来了,要是按照一般的 HMAC-MD5 实现的话,也就是
1 | |
但是经过验证,这样得到的结果和 hook 到的 digest 是不一致的,另外,在 final digest 前还有 16 字节的输出还没弄清来源
将中间状态也 hook 出来
1 | |
贴一段输出
1 | |
看到了 MD5 IV,以逆序存放
A=0x10325476 B=0x98badcfe C=0xefcdab89 D=0x67452301
同时也看到了 inner = md5(A + message)
1 | |
这里的 A B C D 拼起来 inner = 77df887f837dcf676b25a3b61b59ca27 正是最终摘要前的 16 字节
之后计算 md5(B + inner)
1 | |
这个输出就是 final degist
不过按照标准 md5 还原的话与 hook 的结果是不一致的,应该做了魔改处理,这里就不展开了,总的链路已经梳理的差不多了,剩下的就是纯粹的算法逆向了
之后分析出来的结果这个 md5 除了上面的 IV 逆序外,旋转方向和位数也变了,第一轮右移的参数是 26,19,15,11,25,20,15,12,25,20,16,10,25,19,15,10,等价于左移 6,13,17,21,7,12,17,20,7,12,16,22,7,13,17,22,而标准的 md5 第一轮是左移 7,12,17,22 重复
另外它的 md5 k 常量表也与标准的不一样
1 | |
魔改 AES
除此之外,上面 HMAC 中的 A B 块的数据异或前也是经过了加密的,因为 A B 块本身是通过一个 key 分别异或 0x36 和 0x5c 得到的,而这个 key 就是通过一个魔改 AES 得到的,其实就是白盒 AES
先用 deviceId 派生 AES-128 的 key,步骤如下:
1 | |
然后进行密钥拓展,用了 TBox_1 ~ TBox_4 来模拟 AES 的字节替换、循环左移和轮密钥加的操作
1 | |
本质上就是在做
1 | |
最后把加密轮密钥变成解密轮密钥,先反转轮密钥顺序,再用 TBox_2 + TBox_5~8 预处理成解密轮密钥
在 .rodata 可以找到 8 个 T 盒,每个都是 1024 字节
0x18198 处 TBox_1:
1 | |
0x18598 处 TBox_2:
1 | |
0x18998 处 TBox_3:
1 | |
0x18d98 处 TBox_4:
1 | |
0x17098 处 TBox_5:
1 | |
0x17498 处 TBox_6:
1 | |
0x17898 处 TBox_7:
1 | |
0x17c98 处 TBox_8:
1 | |
之后的对提取出来的 hmac_string 进行解密,先将其进行 Base64 解码,得到原始密文再转成 hex,一共 96 字节,在进行 aes 解密,每轮用 TBox_5 ~ TBox_8 查表,完成 AES 的字节替换、行移位、列混淆、轮密钥加的步骤,并且是 CBC 模式,有块异或的操作,初始 IV 是固定值 31 01 32 34 04 02 08 61 66 7A 66 66 07 17 66 39,最后一轮用逆 S 盒完成字节替换,行移位,轮密钥加的步骤,所有 6 个块解完后去掉前 16 字节和后 16 字节,只保留中间的 64 字节,再后续的 HMAC-MD5 中去异或 0x36 和 0x5c 分别得到 ipad 和 opad
总流程
原始数据:build_id 即 APP 版本号 、device_id 即设备 uuid 、hmac_string (从 data/data/com.xingin.xhs/shared_prefs/s.xml 中提取)
对 build_id 进行密钥拓展得到 AES 解密轮密钥, hmac_string 经过魔改 AES 解密得到 64 字节和 message 一起传入 HMAC-MD5 得到 16 字节摘要,最后是一个 RC4 + Base64,最后的生成结果前加上 XY 就是 shield 的最终参数